아래 url에 기재된 유튜브를 바탕으로 그레인저 인과성 검정을 공부를 위해 학습한 내용을 필사하였습니다.
https://youtu.be/b8hzDzGWyGM?si=m8EoMTUsA1ZIehlh
Granger Causality , 파이썬 코드를 통한 그레인저 인과성 검정을 하기 위해 해당 강의를 참고하였습니다.
https://youtu.be/4TkNZviNJC0?si=ljNENO-CgCmGwQGT
그레인저 인과성 검정에 대해서 간단하게 배워보려고 한다.
그레인저 인과성 검정을 알기전에 VAR모형에 대해서 알아본다.
앞에서 계속 배워웠던 시계열 모형 중에서 AR(p) 모형은
Yt 를 종속변수로 두고, 독립변수는 t시점 이전의 Yt-1, .. Yt-p 자신의 과거로 사용하며
이 해당 모형에서 {Yt}라는 확률과정이 생긴다.
그런데 사실 이 경우는 '하나의 시계열 (one time series)' 을 보는것이다.
이제부터 하나의 시계열에서 확장해서 여러개의 시계열을 확장하자
만일 데이터가 여러개의 시계열이 있고 이 시계열들의 상호작용을 고려한 모형에
해당 데이터를 적합하고자할때 쓰이는 모형이 벡터자기회귀모형이다.
벡터자기회귀모형(vector Auto regression)은 하나의 시계열(one time series)에만
초점을 두지않고, 여러개의 시계열 즉 여러개의 확률과정 (multiple time series) 와
더불어 이 확률과정 간의 상호작용(interaction)을 고려한다.
그리고 이 상호작용은 구체적으로 '하나의 시계열(time series)가
또다른 시계열(time series)의 원인(cause)인가 아닌가에 대한 내용이다.
예를들어
내가 어떤 동네에 살고 있고 이 동네의 집값이 오르게 되었다고 가정해보자.
그렇다면 자연스럽게 이 동네의 주변 동네의 집값도 오를것이라고 생각해볼 수 있다.
이렇게 자연스럽게 생각해볼수 있는 이유는 지역적으로 가까이 묶여있기 때문이다.
이 상황에서 두개의 시계열(two time series)를 생각해 볼 수 있는데
하나는 {Yr} : 우리 동네의 집값 이고
또 다른 하나는 {Xt} : 우리 동네 옆의 집값 으로 생각해 볼 수 있다.
근데 이 두 개의 시계열이 연관되어 있을 수 있다는 것이다.
어쩌면 우리 동네의 집값상승이 원인이 되어
우리 동네 옆의 집값 상승의 결과를 일으킨것이 아닐까 ? 라고 생각해 볼 수 있다.
데이터를 통해 연관관계가 있는지 혹은 심화적으로
인과관계가 있는지 파악하는 것은 해당 예시의 경우 미래의 집값을 예측(predict) 할때 도움을 준다.
따라서 이제부터 이러한 인과관계가 있는지 단순히 추측하기 보다
수학적으로 어떻게 파악할수 있는지 살펴보고자 한다.

여기 왼쪽은 부자 도시이고
오른쪽은 가난한 도시가 있다.
두 동네는 공통점이 있는데 그건 두 도시 모두 매년 특정한 양의 재화를 수출하려고 한다는 것이다.
그래서 위의 그림에서
rt : 1년에 부자도시에서 수출된 재화의 양
Pt : 1년에 가난한 도시에서 수출된 재화의 양이다.
예를들어 r1과 P1은 각각의 도시에서 첫해( year 1 ) 에 수출된 재화의 양이 된다 .
이때,
가난한 도시는 재정 적자나 부채 상태에서 벗어나려고 한다는 점을 주목하자 (가정)
가난한 도시는 재정적으로 더 건전해지고 싶어해서
부자 도시를 일종의 기준으로 삼는다.
즉 가난한 도시는 부자 도시의 수출량을 보고 이 값을 기준으로
이 전년도의 부자 도시의 수출량과 동일한 값으로
자기 도시(가난한 도시)의 올해 수출량을 정하기로 한다.
(영상에서 이 말에 대한 또 하나의 언급으로는
금융, 경제에서 꽤 흔하다고 한다.
심지어 정부나 국가 단위에서도 가난에서 벗어나려는 한 나라가
더 부유한 나라의 통화에 자기 나라의 통화를 연동(link) 시키는 경우가 있다고 한다.
(ex). 인플레이션 목표를 다른 나라에 맞춰 따라가는 정책
이렇게 하는 이유는 이러한 단순한 조치만으로도
가난한 나라가 빈곤 상태에서 벗어나기를 기대하기 때문이다. )
아무튼 가난한 도시가 이전년도의 부자도시의 수출량와 똑같은 수출량을 올해
수출하기로 하는 전략을 선택하겠다고 결정했다면
다음과 같은 그래프가 나타날 것이라고 생각해 볼 수 있다.
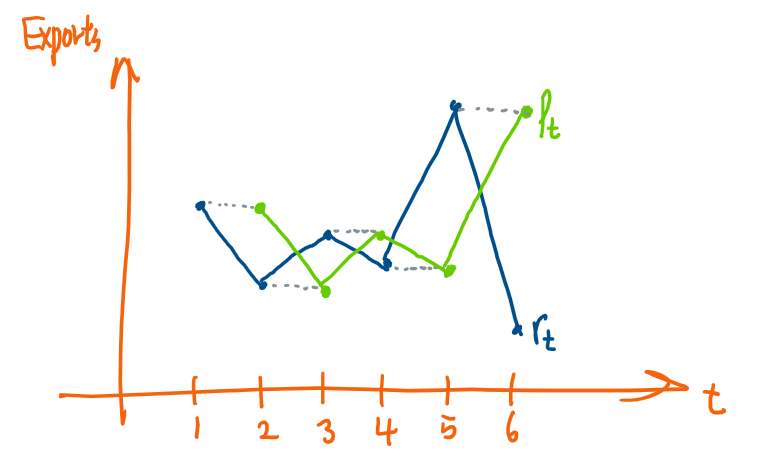
위의 그래프는 시간에 따라서 가난한 도시와 부자도시의 수출량을 나타낸 그래프이다.
가난한 도시가 부자 도시의 전략을 그대로 따라 했다고 생각할 수 있으므로
부자 도시의 직전 과거값이 동일하게 가난한 도시의 당해 년도의 수출량이 되므로
부자 도시의 수출량 그래프를 이동(shift) 한 그래프가
정확하게 가난한 도시의 수출량 그래프가 된다.
이는 하나의 시계열이 또 다른 하나의 시계열과 어떻게 연관(link) 되어 있는지
기하적으로(그래프로) 설명한 내용이다.
이제 수학적으로 설명하는데 하기전에 인과성(Causality)가 무엇인지 명확히 하고자 한다.
두개의 시계열이 어떤 방식으로 연결되어 있어서
한 시계열을 다른 시계열의 시차(lagged values)를 보고 아주 잘 예측할 수 있는 상황이면
(위의 예시의 경우
부자 도시의 과거 수출 값을 하면 가난한 도시의 수출전략을 잘 예측할 수 있었다.)
이를 one time series Granger causes the other 이라고 한다.
이 부분에 중요한 점은 꼭 Granger causality 라고 이름을 붙여야한다는 것이다.
그냥 causality라고 하면 안되는 이유가
인과관계라고 말하기 위해선 훨씬 더 까다로운 조건과 증명이 필요하기 때문이다.
실제로 진짜 원인이 무엇인지는 알수 없고
단순히 하나의 시계열이 다른 시계열을 예측하는데 매우 도움이 된다 정도 만 알고 있기 떄문에
causality 라고 표현하지 않고 다소 완화된 개념으로
Granger causality라고 표현한다.
위의 예제의 경우
"부자 도시의 수출전략 Rt가 가난한 도시의 수출 전략 Pt를
Granger cause 하고 있다(Granger causing)" 라고 표현한다.
도식화 하면 다음과 같다.

그럼 이제 이걸 그래프로 판단하지말고 수학적으로 확인하는 공식을 살펴보기로 한다.
단계별로 진행된다.
첫번째 단계는 Pt 를 종속변수로 두고
이와 잘 맞는 AR모형을 찾는다.
(이를 위해서 PACF(부분 자기상관함수)를 사용할 수 있는데
PACF는 ACF와 마찬가지로 시계열 자료의 종속성을 파악할 수 있으며
또한 AR 모형에 어떤 시차(lag)까지 포함해야하는지 파악할 수 있다.)
(PACF는 추후 포스팅할 계획입니다! ) )
예를들어 다음과 같은 결과를 얻었다고 하자.

{Pt} 은 해당 모형에서 얻어진 시계열이라고 하면,
Pt의 다음 미래값을 예측하기 위해선, 직전값과 시차가 3떨어진 과거값을 사용하면 된다는 것을 알게된다.
이를 base model (기본 모형) 이라고 한다.
해당 모형에는 부자 도시의 대한 정보가 있지 않다.
그 이유는 추가 정보를 넣지 않았을 때 가난한 도시의 수출량을 어느 정도까지 예측가능한지 먼저 확인하는 단계이기 때문이다.
만일 가난한 도시의 수출 전략의 과거값들만 사용해서 만든 모형(base model) 에서
만든 예측이 부자 도시의 정보를 추가해서 만든 모형에서 만든 예측과 비교했을때
예측력에서 거의 차이가 없다면
부자 도시 정보는 굳이 필요하지 않고
부자 도시의 수출전략은 가난한 도시의 전략을 Granger cause 하지 않는다 라고 말할 수 있다.
두번째 단계는
이제 해당 base model에 부자 도시의 수출 에 관한 항인 rt 을 추가한다.
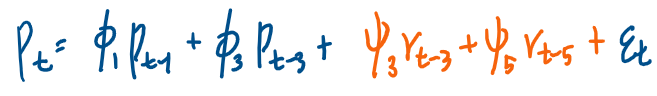
그러나 base model 모형의 예측력을 비교하기전에
'rt와 관련된 항'을 추가한다고 했는데
지금 이 경우 rt-3와 rt-5을 골랐다.
여기서 하필 무수히 많은 부자 도시의 t 시점 이전 과거값들중 이 값들을 어떻게 골라내었는지 생각해봐야한다.
이 과정은 다시 세부적으로 두 단계로 이루어진다.
먼저 여러가지 다른 시차를 고려해본다
예를들어 rt-1, rt-2 를 모형에 넣어보고
(사실 어떤 시차를 고려할지 도와주는 여러가지 방법이 있지만 지금은 여러 시차들 중 몇개를 후보로 선택하는 방법을 생각해본다.)
다음에는 각 시차마다 t-test를 수행한다.
해당 t-test는
"특정 시차 하나가 가난한 도시의 수출 전략을 예측하는데 의미있는가(meaningful)를 알려준다"
데이터를 모형에 적합한 후 t-test 검정을 통해서
귀무가설을 특정 시차의 계수가 0 이다.
대립가설을 특정 시차의 계수가 0이 아니다. 를 통해서
만일 유의하다면 해당 시차는 남기고 유의하지 않다면 해당 시차는 버린다.
t-test를 하게된 결과
가난한 도시의 수출량을 예측하는데 도움이 되는 부자 도시의 과거 t시점의 몇개의 시차들만 남게된다.
그 다음으로는
이렇게 골라낸 시차들을 한꺼번에 모아서 F-test를 수행하는 것이다.
F-검정은 이 여러개의 시차들을 함께넣었을떄
이들이 집합적으로 가난한 도시의 수출 전략을 예측하는데 의미있는가
즉 모형의 유의미성을 test한다.
구체적으로 만일 t-test의 경우 선별된 모든 시차들이 유의미했지만
F-test 결과 모형이 유의미하지않다고 하면
해당 시차들을 모두 버린다.
두단계를 거치고 나서
최종적으로 rt-3와 rt-5가 t-test와 F-test를 통과했다고 가정하자.
즉 두 시차는
가난한 도시의 수출량을 예측하는 데 유의미하게 도움이 된다는 뜻이고,
그래서 이 두 시차를 최종 모형에 포함해서 유지한다는 결론이 된다.
이제 세번째 단계는 결론을 내는 것이다.
만약 최종 모형에 부자 도시 수출량의 시차가
적어도 하나이상 포함되어 있다면
" 부자 도시의 수출량이 가난한 도시의 수출량을 Granger cause 한다 " 라고 말할 수 있다.
최종 모형에 부자 도시 수출량에 대한 시차(ex.rt-3 , rt-5) 가
하나라도 포함되어 있다면 이는
부자 도시 수출량의 시차에 대한 정보를 알고나면
가난한 도시 수출량에 대한 예측력이 유의미하게 좋아진다는 것을 확인했다는 뜻이다.
이 관계가 바로 Granger causality 이다.
반대로 t-test와 F-test 를 모두 거쳤는데
부자 도시 수출량의 어떠한 시차도 통계적으로 유의하지 않다는 결과가 나오면
이 말은 곧
1단계에서 만들었던 가난한 도시의 AR모형에
부자 도시 수출 전략의 시차 정보를 아무리 넣어도 모형이 더 좋아지지 않는다는 것을 의미한다.
이 경우
"부자 도시의 수출량은 가난한 도시의 수출량을 Granger cause 하지 않는다" 라고 한다.
<요약>
- Granger casuality의 직관적인 개념
- 한 시계열의 과거 값이 다른 시계열의 미래를 예측하는 데 도움이 되면,
그때 우리는 Granger causality라는 개념을 쓴다. - 즉, “한 시계열이 다른 시계열을 예측적으로 이끈다”는 아이디어다.
- 한 시계열의 과거 값이 다른 시계열의 미래를 예측하는 데 도움이 되면,
- Granger causality ≠ 진짜 인과관계
- Granger causality는 진짜 인과관계(causality) 자체는 아니다.
- 다만, “A가 B를 예측하는 데 유용하다”는 의미에서
조금 완화된 인과 개념이라고 볼 수 있다. - (그래도 여전히 매우 유용하다고 합니다.)
- 수학(통계)적으로 판단하는 3단계 절차
- (1) 원래 하나의 변수에 대한 BEST AR(p) 모형 적합 (= base model 만들기)
- (2) 다른 시계열의 시차들을 넣고 t-검정, F-검정 (= 세부적인 두단계) 으로 유의한지 확인
- (3) 유의한 시차가 적어도 하나 이상 최종 모형에 남아 있으면 “Granger cause 한다”고 결론
파이썬을 통해 간단하게 granger casuality 를 검정해본다.
데이터는 AR모형에서 시뮬레이션을 통해 생성하기로 한다.

t1과 t2 라는 두개의 시계열을 만들것이고
t1과 t2 는 직전 시차의 계수가 0.5 인 AR(1) 모형을 따른다고 가정한다.
(주어진 데이터가 아닌 모형에서 생성된 데이터(simulated)를 사용하였습니다)

단 t2의 경우 t1과 달리 각 시점마다 random noise를 추가한다.
그다음 t2라는 시계열은 t1 시계열의 3개월 뒤로 밀려난 데이터로 임의로 설정한다.
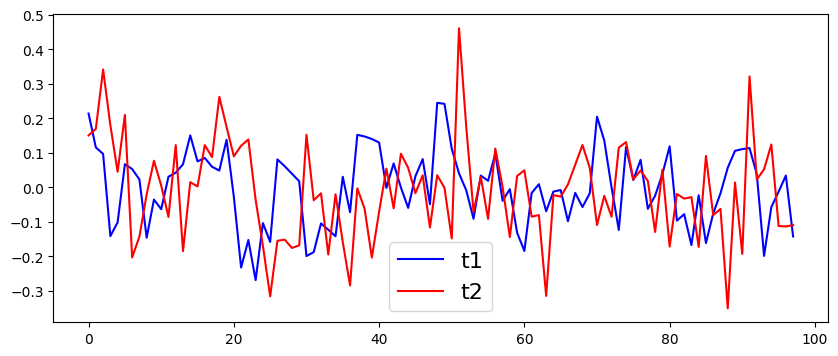
모의로 어떻게 생성되었는지 모른다고 가정했을땐
그래프로 판단하기에 t1을 이동시킨 데이터가 t2와 비슷하다는 점을 파악할 수 있었는데
이러한 관계를 통계적으로 즉 코드로 어떻게 포착하는지 파악해보기로 한다.
grangercasuality test를 하기전에 test에 넣어줄 옵션중 하나인 데이터를 다듬어야하는데
이 경우 매우 중요한점은 첫번 째 열에는 'Granger 인과성을 받는 시계열(위의 예제의 경우: 가난한 도시가 된다.) '
, 두번째 열에는 'Granger 인과성을 주는 시계열, 즉 원인이 될 수도 있는 후보(위의 예제의 경우: 부자 도시가 된다.)'
을 무조건 지켜서 넣어야 한다.

지금 해당 예제의 경우 , t1에 의해 t2가 Granger cause가 되는지? 확인하는 것이 목적이므로
t2를 첫번째 열에, t1을 두번째 열에 넣는다.
데이터를 다듬었다면 이제 grangercausalitytests라는 함수에
데이터와 그다음 최대 시차개수(maxlag)을 넣으면된다.
예를들어 밑의 그림의 경우 3을 넣었는데 이 말은
'1시차, 2시차 , 3시차에서 Granger 인과성이 있는지 차례대로 검사한다' 라는 뜻이다.
원하는 만큼 시차의 개수를 줄 수 있다.
test 하기전에 유의수준을 0.05 라고 하자.

결과를 본다면,
먼저 1시차만 고려했을때,
grangercausalitytests라는 함수는 4가지 검정을 수행하고 있다.
각 검정에 대한 p_value을 알 수 있고
해당 p_value는 유의수준 0.05 보다 모두 크기 때문에
1시차만 보았을때는 t1이 t2를 Granger cause 한다고 보기 어렵다고 말할 수 있다.
그 다음, 2시차까지 보는 경우를 살펴보면,
p-value들이 모두 0.001 전후로 매우 작다.
즉 2차시까지 고려했을 때, t2라는 시계열은 t1이라는 시계열을 Granger cause한다고 말할 수 있다.
3시차까지 포함해서 보면, 네 가지 검정에 대한 p-value가 모두 0 또는 거의 0에 가깝게 떨어진다.
이는 “3시차까지 고려했을 때, t1이 t2를 Granger cause 한다는 매우 강한 증거가 있다”는 뜻이다.
해당 결과를 통해
위에서 t2라는 시계열은 t1 시계열의 3개월 뒤로 밀려난 데이터로 임의로 설계해둔 바가
검정결과에 그대로 드러났다고 생각할 수 있다.
'시계열자료분석' 카테고리의 다른 글
| 시계열_ch4 The General Linear Process Version of the AR(1) model (0) | 2025.11.09 |
|---|---|
| 시계열_ch4_4.3 Autoregressive Processes (1) | 2025.10.11 |
| 시계열_ch4_4.2 Moving Average Processes (0) | 2025.10.09 |
| 시계열_ch4_4.1 General Linear Processes (1) | 2025.10.09 |
| 시계열_ch2_2.3(Stationarity) (0) | 2025.10.08 |