2.3 Stationarity (정상성)
모형화를 할때, 데이터의 특성을 잘 파악하고
파악했다면 해당 특성을 잘 적용시키는 모형을 골라야한다고 배웠다.
데이터의 특성 중에 '정상성'이 있는데
정상성의 특징을 가지는 데이터들에 적용할 만한 모형들을 시계열 모형에서 배우게 된다.
그래서 먼저 정상성이 무엇인지 파악해본다.
정상성은 시간이 흘러도 어떠한 성질이 변하지 않는 특성을 가진다.
정확히 말하면 확률과정이 다음과 같은 3가지 조건을 만족한다면 그 확률과정을 정상확률과정(stationary process)라고 한다.

①과 ②는 개별 시점에 대해서만 얘기하는 특성이다.
①은 다른 시점간 확률변수의 기댓값이 일정하다는 내용이고
②는 다른 시점간 확률변수의 분포가 일정하다(폭이 일정)는 내용이다.
③은 두변수간의 선형관계에 대해서 얘기하고 있는데,
정상 확률과정의 경우, 두 확률변수간의 선형 상관관계는 h에만 의존하는 함수로 표현되어야한다는 점이다.
즉 시차에만 의존하고, 시간이 흘러도 시차가 동일하다면 두 확률변수간의 선형관계는 변하지 않는다는 뜻이다.
예를 들어서 과거에는 그 전의 값이 다음값에 약하게 영향을 주었지만 시간이 흘러서 그 전의 값이 다음값에 강하게 영향을 주었다면 이때의 {Xt} 확률변수들의 집합은 정상 확률과정을 따르지 않게된다.
그러나 정상 확률과정의 경우
X1 과 X2간의 상관계수의 값과 시간이 흘러서 X100 X101 간의 상관계수의 값과 같게 된다.
ch2_2.2절와 2.3절에서 배웠던 예제 2번 문제를 다시 보자
예제 2번 문제에서 언급한 {Xt}라는 확률과정을 path를 500개 만들어서 시각화 해보면 다음과 같다.
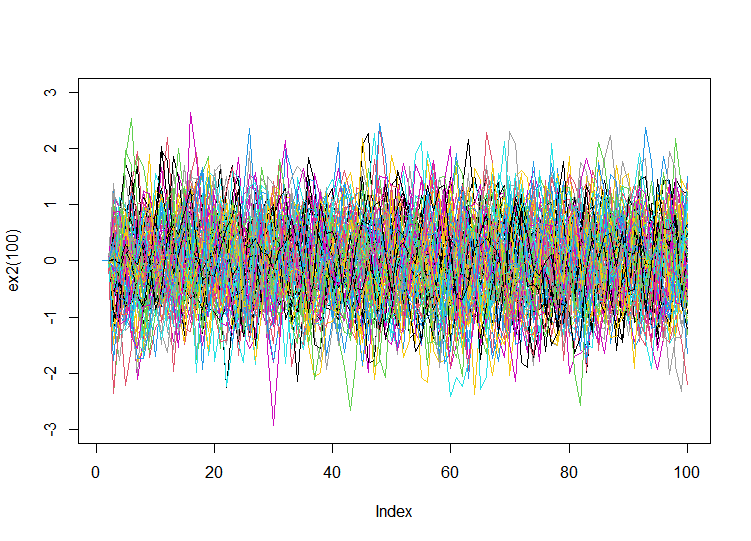
예제 2번의 문제에서 세운 모형으로부터 생성한 확률변수들의 집합 {Xt}의
평균은 모든 시점에서 0으로 정상성 조건 ①을 만족한다.
분산은 모든 시점에서 σ^2/2 로 정상성 조건 ②를 만족한다.
그리고 이 두가지 조건은 path를 시각화 한 위의 그래프에서도 충분히 엿볼 수 있다.
확률변수의 각 시점마다 0을 중심으로 값이 안정적으로 나타나고 있으며 폭도 각 시점마다 일정함을 볼 수 있다.
정상성 조건 ③은 시계열 자료를 시각화해도 잘 알기 어려울 수 있다
일단 예제2의 경우 상관계수가 h에 따라서 값이 바뀌고 t에 따라서는 값이 변하지 않으므로 정상성 조건 ③을 만족함을 알 수 있다.
즉 예제의 확률과정은 정상 확률과정이라고 말할 수 있다.
예제2를 통해서 정상성인지 아닌지 여부를 파악을 해보았는데 정리해보면
정상성 조건 1의 경우 path가 어떤값을 중심으로 나타났는지 확인해보면 되고 정상성 조건 2를 만족하는지 여부를 파악하기 위해선 path가 일정한 범위에서 나타났는지 확인해보면 된다. 그러나 corrleation의 경우, path를 통하여 살펴보기는 쉽지 않다. 그렇다면 두변수간의 관계를 어떻게 파악하면 좋을까?
앞서 chapter1에서 ACF 자기상관함수를 언급한적이 있다.
ACF를 통해서 정상성 조건 3을 만족하였는지 파악한다.
우선 정상확률과정의 ACF를 고려해보자
ACF = auto correlation function를 뜻하고
Auto는 집합에서 두개의 변수를 꺼내온다는 의미를 가지고 있고
C는 상관계수를 의미한다.
정상성 조건 3에 의해서 두변수간 상관계수는 h만의 함수로 쓸 수 있어서
ACF는 h에 따라 상관계수를 출력해주는 함수로 생각할 수 있다.
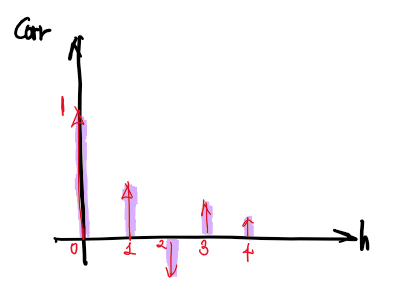
그래서 모형의 ACF를 보고 모형화를 할때 모형을 선택하게 된다.
그런데 정상확률과정의 경우에서, 상관계수의 식을 다시한번 보면,
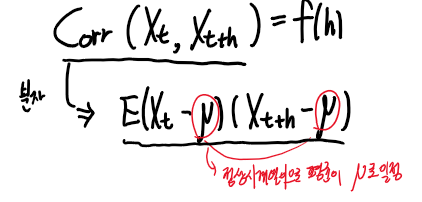
상관계수의 분자를 계산하기 위해선, (Xt, Xt+h)의 결합분포가 필요하다.
이를 알아야 상관계수를 구할 수 있는데, 분포를 알기에는 어렵다고 배웠다.
따라서 주어진 데이터를 이용해서 ACF를 계산하는데 이를 sample ACF라고 하며, 이를 구체적으로 구하는 방법은
추후의 장에서 배우게 된다.
결론적으로,
모형을 찾기전
데이터간의 종속성이란 데이터 특징을 발견했다면,
ACF를 통해 해당 특성을 잘 반영해주는 모형을 찾아, 조금 더 정확하게 다음 값을 추론할 수 있을 것이다.
그래서 앞서 말했던 의사결정 방식을 도식화해보면 다음과 같다.

이전까지 stationary process의 정의를 배웠다.
그러나 위의 도식화에선 staionary model이라는 용어가 나오는데 둘의 개념이 조금 다르다.
stationary model은
예를 들어 model로부터 확률과정들이 만들어지는데
그 확률과정이 정상성 특징을 가진다면 이때 model을 stationary model 이라고 한다.
앞으로 4장에서 점화식 형태로 서술된 시계열 모형들이 등장하게 되는데
이때 시계열 모형들이 만들어내는 확률과정이 정상성을 띠는지 확인해보고
과연 해당 시계열 모형이 stationary model인지 아닌지 여부를 확인해 볼 수 있을 것이다.
다음으로 백색잡음(White noise)의 정의를 살펴본다.
백색잡음도 확률과정으로 {Xt} 확률변수들의 집합으로 표시될 수 있다
확률과정이 다음과 같은 조건을 만족한다면 백색잡음이라고 정의한다.

③ 번 조건의 경우 두 시점 사이에 선형관계가 없다는 뜻이다
그러나 3번조건을 만족한다고 해서 두 확률변수간 독립이다라고 말할 수 없다.
(독립은 아무런 관계가 없음을 의미하기때문)
그런의미에서 만일 iid 특징을 가진 확률변수들의 나열을 생각해보자
이 나열 또한 {Xt}로 표현할 수 있고
iid 특징에 따라서
백색잡음의
①번 조건을 만족한다.(각 확률변수들의 평균은 0이다.)
②번 조건을 만족한다.(각 확률변수들의 분산은 σ^2으로 일정하다.)
③ 번 조건을 만족한다.(각 확률변수들은 독립이므로 따라서 선형관계도 가지고 있지않는다.)
iid sequence인 경우 백색잡음이 된다.
그러나 백색잡음가 iid sequence가 되려면
독립임을 만족해야하는데
③ 번 조건 만으로 충분하지 않아서 백색잡음은 iid sequence라고 말할 수 없다.
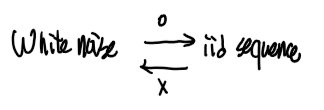
'시계열자료분석' 카테고리의 다른 글
| 시계열_ch4_4.2 Moving Average Processes (0) | 2025.10.09 |
|---|---|
| 시계열_ch4_4.1 General Linear Processes (1) | 2025.10.09 |
| 시계열_ch2_2.1 , 2.2 (0) | 2025.10.07 |
| 시계열_ch1_introduction_(2) (0) | 2025.10.05 |
| 시계열_ch1_시계열자료의 뜻 (0) | 2025.09.28 |