<ch2 하기전에 잔차에 대한 설명을 먼저 짚어보기>
회귀분석 수업에서 모형진단이라는 내용을 배웠는데
모형진단은 잔차분석을 통해 이루어진다.
잔차란 오차항에 대한 추정량(치)이다.
통계량 중 추정할 때 사용되는 통계량을 추정량이라고 하기 때문에
잔차는 오차를 추정하기 위해 사용되는 통계량이다.
오차를 추정하는 이유는 오차를 눈으로 볼 수 없기 때문이다.
Y = f(X) + ε 에서 X가 설명할 수 없는 부분을 ε에 넣어주는 상황에서,
Y, X는 관찰되는 반면,
아직 X와 Y의 관계를 파악하지 못한 상황에서 X의 함수값을 모르기 떄문에
ε는 관측할 수 없다.
X와 Y의 관계를 파악하고자 하기로 생각했다고 가정하면,
회귀분석을 시행할텐데 회귀분석은 오차항( ε ~ iid N(0, σ^2) ) 에 대해서 가정을 둔다.
그런데 앞서 말했듯이 오차를 볼 수 없는 상황이라 대체재가 필요하다.
그래서 X축에 따라 첫번째 오차항을 얼마로 추정할지 데이터로부터 계산하고,
두번째 오차항을 얼마로 추정할지 데이터로부터 계산하여
이 과정을 반복하는데,
이렇게 계산된 값들을 가지고 오차항을 추정하는데 이때 계산된 값들을 잔차라고 한다.
그래서 만일 회귀분석의 가정을 두고 있다면,
오차 대신 잔차들이 ε ~ iid N(0, σ^2) 라는 가정 , 즉
잔차들이 세개의 가정을 만족하고 있는지 판단하고 이 과정을 '잔차 분석' 이라고 한다.
잔차들의 세가지 가정
1) 잔차들이 0을 중심으로 퍼져있는가? -> 오차항의 가정 중 오차항의 평균이 0 인지 판단하기 위함
2) 잔차들의 폭이 일정한 범위안에 나타나는가? -> 오차들의 분산이 일정한지 판단하기 위함
3) 잔차들이 특정한 패턴없이 무작위로 퍼져있는가? -> 오차들이 서로 독립인지 판단하기 위함
위의 내용은 회귀분석의 경우, 어떻게 잔차분석을 시행하는지에 대한 내용이었지만
시계열 모형에서도 오차항이 들어있다.
따라서 회귀모형처럼 오차항에 대한 어떠한 가정을 내린뒤,
모형진단 단계에서 해당 가정을 체크하는 잔차분석을 진행한다.
<ch2>
2.1 Time Series and Stochastic Processes
2장에선 시계열에 대한 기본 개념들(시계열, 확률과정, 평균,분산, 공분산, 정상성)에 대해 배운다.
먼저 확률과정이란
영어로 stochastic process라고 하고 random process라고도 한다.
확률과정을 표현할때
sequence of random variables 라고도 표현할 수 있고
조금더 포괄적인 개념으로 set of random variables로 표현할 수 있다.
sequence는 한국어로 '열'을 뜻한다. 순서대로 "나열"할 수 있다면 모두 sequence에 해당된다.
만약에 실수들을 나열한다면 실수열이 되고
확률변수들을 나열한다면 '확률과정'이 된다.
이산형확률변수를 나열했다고 생각해보면,
각각의 확률변수에대가 자연수 번호를 매길 수 있지만
연속형 확률변수일 경우 각각의 확률변수에다가 자연수 번호를 매기기 힘들다.
따라서 같은 표현이지만 조금더 포괄적인 개념인 set of random variables로 확률과정을 표현한다.
앞으로
확률변수들의 집합을 확률과정이라고 하고
집합의 원소는 확률변수가 된다.

① 의 예시에서 만일 t = 1, 2, 3 가 시간의 개념이라면,
①은 시계열 자료가 된다.
즉 시계열자료는 확률과정의 부분집합이다.
①과 ②을 A라는 집합을 이용해서 다르게 표현할 수도 있다.

확률과정을 A라는 집합을 이용해서 다르게 표현할 수 있고, 만일 A가 시간일 경우
{Xt | t ∈ A } 라는 집합은 시계열자료가 된다.
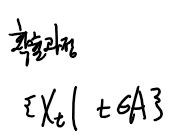
앞서 시계열자료와 iid자료를 비교해본것처럼
확률과정과 확률표본을 비교해보자.
확률표본은 영어로 random sample 이라고 하고
random sample의 동의어가 iid이다.
표현은 다음과 같이 표현한다.
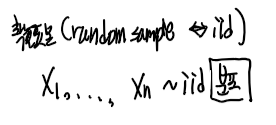
ch1에서도 언급하였지만
확률표본은 모분포에 의해서 결정된다.
그래서 확률표본의 경우 관심있는 대상은 모분포를 통계량 추정을 통해 파악하는 것이다.
반면
확률과정은 데이터간 종속성을 가지고 있기 때문에
관계(종속성)와 각 지점에서의 분포 즉 marginal distribution에 의해서 결정된다.
( marginal distribution 은 하나의 변수에 대한 확률분포를 뜻하고
뒤에서 배울 joint distribution은 둘 이상의 변수에 대한 확률분포를 뜻한다. )
즉 위의 인덱스 표현을 빌리면
확률표본에서 Xi, Xj는 서로 연관되어 있지않아서 문제가 되지 않았지만
확률과정의 경우, Xi, Xj의 관계가 대부분 존재하기 때문에, 변수간의 관계를 파악하는 것이 관심이고,
확률표본과 마찬가지로 Xi자체의 확률분포, Xj자체의 확률분포를 가지고 있다.

t시점에 따라 확률변수가 X1, X2, X3, ... 있을텐데
t=1 시점에서 X1 값이 관찰될것이고,
t= 2 시점에서 X2 값이 관찰될것이다. ...
X1, X2, X3, ..는 random variable이므로 ,
어떠한 값이 나올지 모르지만 그 값을 만들어내는 확률분포가 있을것이다.
근데 확률표본이 아니라 확률과정이므로 똑같은 분포(identical distribution)에서 나온다는 보장이 없으므로,
각 확률변수 X1, X2, X3마다의 확률분포를 위의 그림처럼 표현할 수 있다.
게다가 확률과정의 경우 X1의 분포 와 X2의 분포 , X3의 분포.. 는 서로
연관, 관계가 있기 때문에
확률표본과 다르게 모델을 만들기 위해서 이러한 관계(종속성)을 반영하여 모델을 만들어야한다.
이 관계를 joint probability distribution(결합확률분포)로 나타낼 수 있다.
왜냐하면 결합확률분포는 각 확률변수 자체의 분포도 가지고 있지만,
변수들간의 관계에 대한 정보도 알 수 있기 때문이다.
예를들어 하나의 변수에 대한 정규분포 대신 다변량 정규분포 중 3변량 정규분포의 표현을 살펴보자.

2.2 Means, Variances, and Covariances
평균(mean)과 분산(Variance)는 확률분포의 특징을 표현한다.
X와 Y , 두 확률변수의 확률분포가 같다고 가정해보자
확률분포가 같다면, X와 Y의 기댓값도 서로 같으며, X의 분산, Y의 분산도 서로 같다.
즉 확률분포가 확률분포로 구할 수 있는 특징들을 결정한다.
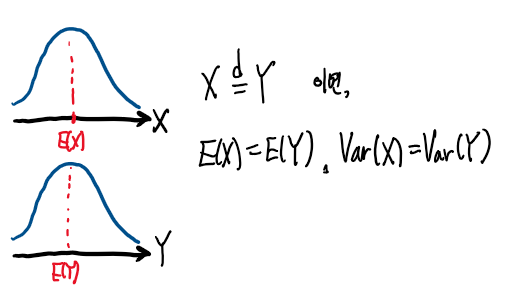
기대값을 수식으로 표현해서, 확률분포가 같으면 기대값이 같은 이유를 살펴보자.
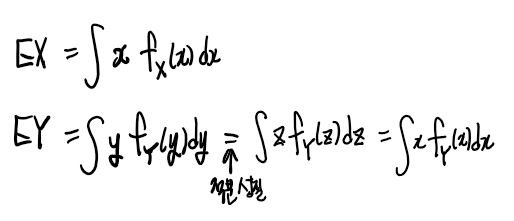
Y의 기댓값을 적분성질에의해서 위와 같이 표현할 수 있는데
이때 두 확률변수의 확률분포가 같다는 뜻은 X의 확률밀도함수와 Y의 확률밀도함수가 같다는 뜻이므로
E[Y]를 다음과 같이 쓸 수 있다.

결국 분포가 E[X]와 Var[X]을 결정한다.
시계열분석의 경우,
시계열자료는 t 시점마다 확률변수 값이 관찰될건데
이경우 t 시점에서의 확률분포의 특징을 E[Xt]와 Var[Xt]가 표현해준다고 생각할 수 있다.
그런데 시계열 데이터의 특징은 한 시점 t = k 에서 값이 하나만 얻어진다.
분포를 알기위해선 t= k 시점에 여러개의 값을 얻고 싶은데, 과거 데이터였기때문에
다시 과거로 돌아가서 관찰하기는 불가능하다.
즉 동일시점(예를들어 t = k) 에서 반복 측정이 불가능하기 때문에 그 시점의 확률분포를 직접적으로 관찰하는 것은 불가능하다.
그러나 나중에 가정을 세워, 데이터 하나를 통해 분포를 추정하는 활동을 해보기로 한다.
(ex. 시계열이 정상적이라는 가정을 세웠다면,
시간 전체에 걸친 여러 시점의 관측값들이 있는 상황에서, 이 값들이 동일한 확률분포에서 추출된 표본으로 보고 분포를 추정해볼 수 있을 것이다.)
다음으로 공분산 Covariance는 두변수간의 결합확률분포에 관계에 대한 정보를 표현한다.
다음에는 시계열 수업에서 다루는 2개의 개념에 대한 정의를 살펴본다.
The autocovariance function 은 자기공분산함수로,
시계열 데이터에서 공분산을 자기공분산이라고 한다.
The autocorrelation function은 자기상관계수함수로
시계열데이터에서 상관계수를 자기상관계수라고 한다.

ρt,s = 0 이라면, 선형관계가 없다는 뜻이고 Yt, Ys are uncorrleated 라고 말한다.
(주의! : independent는 아무런 관계가 없다는 뜻이므로, 선형관계가 없어도 관계가 있을수있으므로
Yt, Ys are uncorrelated라고 말할 수 없다.)
평균,분산, 공분산에 대해서 배웠다.
이제 시계열 모형이 주어질텐데,
이 모형에 의해서 만들어지는 확률과정의
각 시점에서의 기대값, 분산, 자기상관계수을 구해보자.
(지금부터 시작! 예제끝나고 앞으로 여러 시계열 모형의 기대값, 분산, 자기상관계수를 구해야하는데
그러기 위해선 앞에 iid자료와 시계열데이터자료가 무슨의미인지, 대문자,소문자의미를 이해해야 안헷갈림)
예제)
주어진 시계열 모형은 다음과 같고 이때 한가지 가정을 한다.
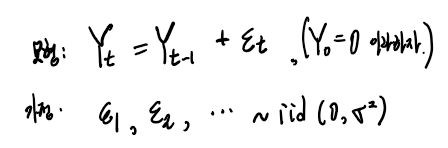
모형과 가정을 잘 생각해보자
우선 모형을 보면,
Yt가 어떻게 만들어지는지 설명하고 있다.
Yt는 t시점 이전값인 Yt-1와 t시점에서의 오차항인 εt가 더해져서 만들어진다.
그리고 t=0시점에서의 Y값은 0이라고 하기로 한다.
Yt는 확률변수인데, 그 이유는 εt가 확률변수이기 때문이다.
가정을 보면,
ε1, ε2, ..., ~ iid(0, σ^2) 에서
ε1은 1번째로 관찰될 확률변수,
ε2는 2번쨰로 관찰된 확률변수이다.
ε1, ε2, ..., 변수는 관찰하기 전까지 값을 정확히 모르고, 값이 흔들리면서 나타나는데
어떤 값은 덜나오고, 더나오고 할 수 있다 즉 가중치가 입혀져서 값이 관측될 것인데
그 가중치를 결정하는 것이 ε의 분포이고, ε1, ε2 ,..., 확률변수는 모두 다 평균이 0이고 분산이 σ^2인 같은 분포에서
값들이 관측될 것이다.
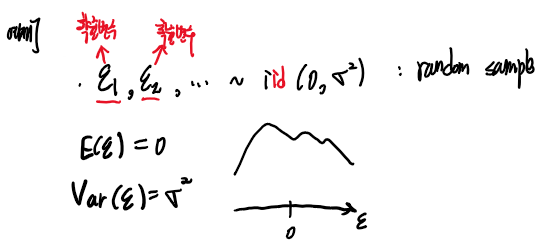
t시점에서의 오차항은 확률변수인데,
만일 오차항이 상수라고 생각해보면, 모형식은 등차수열의 점화식 형태가 된다.
그러나 지금은 오차항은 확률변수이므로 Yt 역시 확률변수가 된다.
그래도 여전히 모형식은 점화식임을 알 수 있으므로, 해당식을 풀어서 쓰면 다음과 같이 Yt를 표현할 수 있다.

즉 Yt는 ε이 t개 합해진것으로 표현할 수 있다.
이 상황에서 Yt의 기대값과, Yt의 분산을 구해본다.


분산 식에서 공분산 텀에 주목하자,
앱실론에 대한 가정에 따르면 각 확률변수 ε1, ε2, .. , εt는 서로 독립(independent가정)이다.
이를 이용해서 공분산 텀을 다음과 같이 풀어갈수 있다.
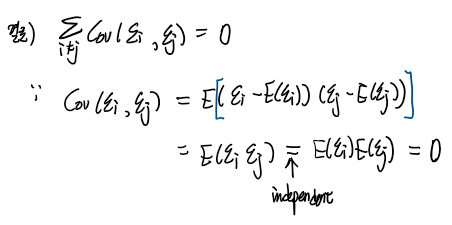
따라서 해당 시계열 모형에서 Yt의 분산을 t에 관한 식으로 표현할 수 있고
즉 시간이 흐를수록 (t가 커질수록) Yt라는 확률변수가 나올 수 있는 값의 범위가 넓어진다고 해석할 수 있다.
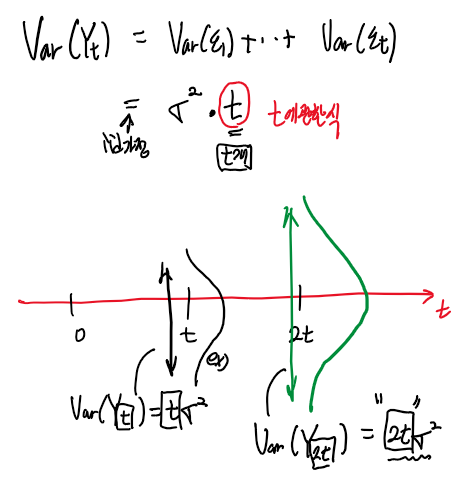
다음으로, 두 시점에서의 확률변수간의 관계를 설명해주는 공분산은
해당 시계열 모형에서 어떠한 식으로 표현할 수 있는지 구해본다.

공분산을 구했으므로 상관계수도 구할 수 있다.

평균, 분산, 공분산까지 구해보았는데
사실 해당 예제의 모형을 random walk 라고 한다.
random walk를 시계열 plot으로 그려보자
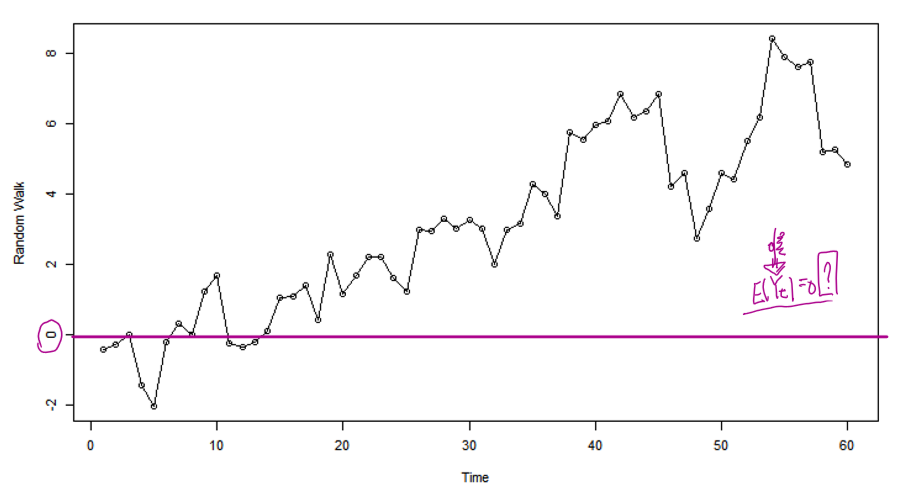
random walk 모형일 경우, 앞서서 이론적으로 Yt의 평균을 계산했더니 0임을 밝혔지만
해당 그래프에선 E(Yt) = 0 임을 보여주지 않는것 같다.
그 이유는 해당 시각화는 수많은 path 들중 하나만을 보여주었기 때문이다.
모형 Yt = Yt-1 + εt에서 각 시점의 εt는 확률변수라고 알고 있다.
즉 시점마다 무작위로 εt값이 발생할 텐데 , 해당 path는 우연히 양수인 값이 여러번 연속적으로 나온 경우이다.
εt가 확률변수이므로 여러개의 경로가 생기게 된다.
(따라서 어떠한 경로는 εt가 우연히 양수가 나오다가 음수가 나오는 형태일수있고
또 어떤 경로는 εt가 우연히 음수인 값이 여러번 연속적으로 나오는 형태일 수 있다.)
이 경우, εt이 매시점마다 어떠한 값으로 실현되는가에 따라 만들어지는 경로를 path라고 한다.
그럼 path 를 여러개를 발생시킨 후, 겹쳐서 그려보자.

위는 path를 500개 그려본 시각화자료이다.
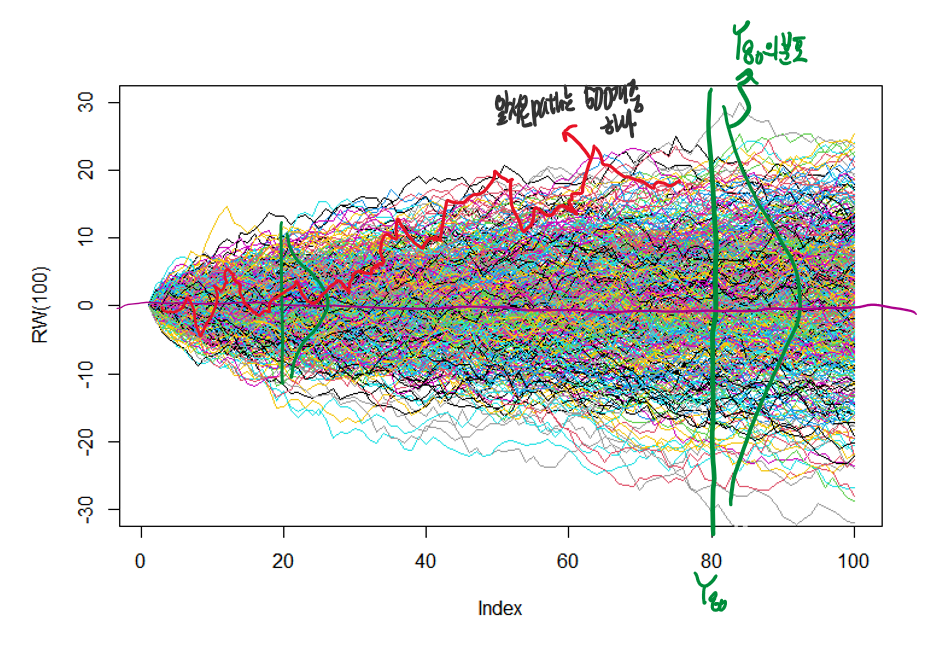
t = 80 시점에서 확률변수 Y80의 기대값이 0일것이라고 생각해 볼수 있다.
또한 random walk의 분산 Var(Yt) = t* σ^2 임을 이론적으로 계산해보았는데
t가 증가할수록 점차 Var(Yt)도 t에 따라서 커지고 있음을 확인해 볼 수 있다.
그리고 앞서 그려본 하나의 path가 500개의 path중 하나임을 알 수 있다.
즉 우리가 분석하고자 하는 시계열 데이터는 무수한 path들중 하나만을 보게 된다.
예제2
모형과 가정은 다음과 같을 때 기대값과 분산, 공분산을 구해보자

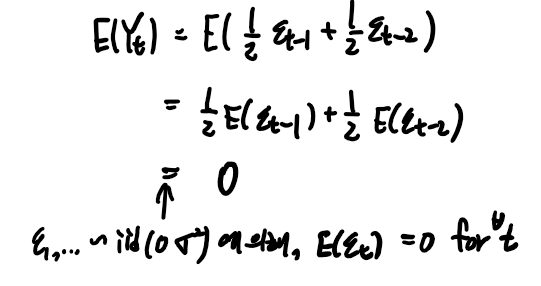
따라서 해당 모형의 경우, Yt의 기대값은 0이다.

random walk 모형일 경우 Var(Yt) 는 t * σ^2 이라서 t에 값에 의존되었지만
해당 모형의 경우 Var(Yt)가 t에 관하여 표현되지 않음을 확인해볼 수 있다.
다음으로 공분산을 계산해보자
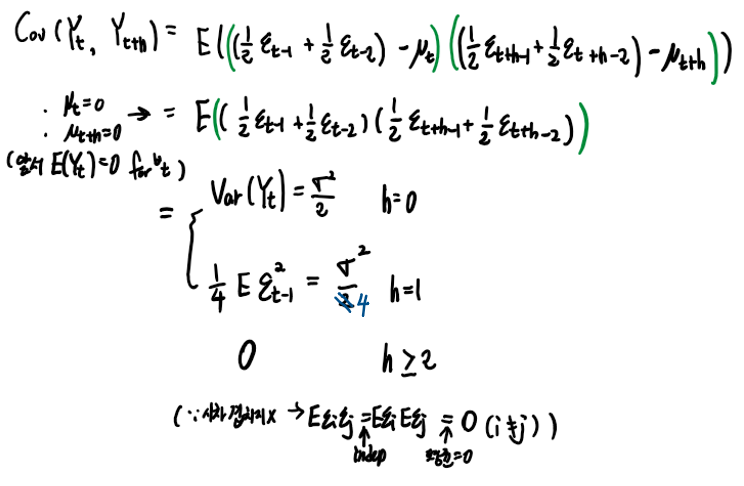
공분산의 값이 h에 따라서 달라짐을 주목하자
h는 t+h - t = h 즉 시차를 의미한다.
시차가 1 차이나는 경우 공분산은 σ ^2/4 이었지만
시차가 2를 초과하는 경우 공분산은 0이 나오게 된다.
'시계열자료분석' 카테고리의 다른 글
| 시계열_ch4_4.2 Moving Average Processes (0) | 2025.10.09 |
|---|---|
| 시계열_ch4_4.1 General Linear Processes (1) | 2025.10.09 |
| 시계열_ch2_2.3(Stationarity) (0) | 2025.10.08 |
| 시계열_ch1_introduction_(2) (0) | 2025.10.05 |
| 시계열_ch1_시계열자료의 뜻 (0) | 2025.09.28 |