다음 그래프를 살펴보자

해당 그래프는 LA지역의 X축은 전년도 강수량, Y축은 전년도 기준 그 다음 강수량을 뜻한다.
이 그래프는 아마 다음과 같은 모델을 염두하고 그린 것이다라고 생각해볼 수 있다.
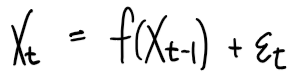
즉 전시점과 다음시점과 관계가 있지않을까라는 생각에서 출발해서
데이터를 통해 위와 같은 그래프를 그려본 것이다.
결국 시계열 데이터 사이는 독립이 아니라 종속관계를 가지고 있는지 확인하는 그래프이다.
이제 다음 시계열 데이터를 보고
다시한번 값과 값 사이에 관계가 있는지 관찰해보자.
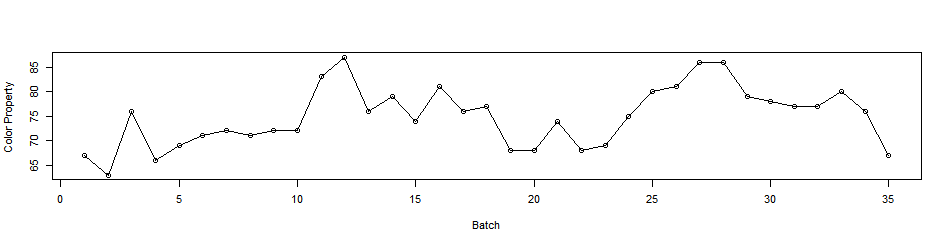
이 그래프를 보았을땐 데이터 사이의 관계를 찾기 쉽지않아보인다.
그래서 같은 데이터를 가지고 이전시점과 다음시점에 대한 산점도 그래프를 그려보자
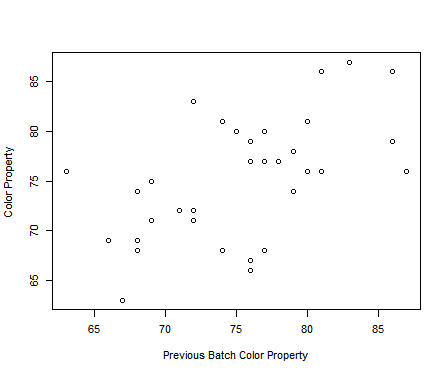
이전 사례와 비교했을땐, 상대적으로 더 뚜렷한 관계가 보이는것 같다.
선형관계가 조금 보인다.
이 관계를 통계적인 식으로 표현할 수 있다
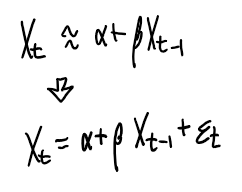
데이터를 가지고 다음과 같은 선형 회귀 모델을 만드는 것도 하나의 모델링 방법이 될 수 있다.
시계열 수업에서 해당 모형은 AR(1) 모형에 해당된다.
회귀분석모델이 시계열 모델로 쓸 수 있는데
잠시만 회귀분석에 대한 가정을 살펴봐야한다.
회귀분석의 가정은 오차항의 평균이 0이어야하며 분산이 일정하고 오차항들이 서로 독립이어야한다.
해당 가정이 만족했을때 회귀계수 즉 우리가 추정해야할 추정치를 사용할 수 있다.
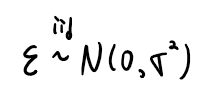
그런데 시계열 데이터를 사용하여 회귀분석의 모수추정 방법중 대표적인 방법인 LSE를 이용하게 된다면
추정치를 쓸수 없게 된다. 그이유는 시계열 데이터에서 오차항들 역시 회귀분석의 가정과 맞지 않기 때문이다.

여기서 말하는 "좋은 성질"이라는건 대표적으로 추정치의 기대값이 모수가 된다는 것인데
시계열데이터로 회귀분석을 진행하였을때 추정량의 좋은 성질 중 어떤 성질이 무너지는가는
다음에 실습을 통해서 파악해보기로 한다.
(-> 추정치에 대해서 과대추정, 과소추정하게 된다.)
다음 데이터를 통해 다시한번 데이터가 서로 연관이 없다는 의미가 무엇인지 생각해보자.
표준정규분포에서 데이터를 500개 뽑는 실험을 진행한다.
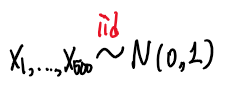
이때 이전값과 그 다음 값의 산점도를 그리면 다음과 같다.
(다음의 코드를 사용하였다.)
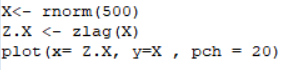

순서쌍이 (Xn-1, Xn)인 점이 산점도에 총 499개가 찍혔고
산점도를 보면, 이전값과 그 다음값의 (선형)상관관계가 없어보인다.
그 이유는 바로 데이터를 생성할때, iid를 가정하고 생성했기 때문이다.
즉 데이터를 random하게( 데이터들이 서로 연관되지않도록) 뽑았음을 확인할 수 있다.
iid자료와 다른 시계열 자료는 데이터들이 서로 연관되어 있음을 기억하자.
'시계열자료분석' 카테고리의 다른 글
| 시계열_ch4_4.2 Moving Average Processes (0) | 2025.10.09 |
|---|---|
| 시계열_ch4_4.1 General Linear Processes (1) | 2025.10.09 |
| 시계열_ch2_2.3(Stationarity) (0) | 2025.10.08 |
| 시계열_ch2_2.1 , 2.2 (0) | 2025.10.07 |
| 시계열_ch1_시계열자료의 뜻 (0) | 2025.09.28 |