시계열 자료란 시간에 따라 얻어지는 자료이다.
시계열 자료가 가지고 있는 중요한 속성은 "종속성"이다.
시계열 자료와 iid 자료를 비교해보자.
iid는 independent, identical distributied 의 약자이다.
즉 iid 자료는
데이터가 관찰이 되는데, 이때
데이터들은 서로 관계가 없으며(= 독립이며)
각각의 데이터들이 만들어낸 확률분포가 모두 동일하다.
그다음 모형화에 대해 알아보자.
두 단어를 살펴보자
observation vs model
observation은 관측치라고 불리는데 그밖에 샘플, 데이터라고도 불린다.
model은 예를들어 시계형 모형, 회귀모형 여러가지 모형이 있다.
이때 observation과 model 사이를 매칭시키는 것이 "모형화"이다.
데이터는 주어져 있는 상황에서
데이터와 잘 맞는 모형을 찾기 위해선
1. 데이터를 관찰해서 데이터의 특징을 파악해야한다.
2. 모형들이 가지고 있는 지식적인 측면을 파악해야한다.
이를 아는 상태에서 , ~~모형이 데이터의 ~~한 속성을 잘 설명해주므로 데이터와 해당 모형을 매칭시킬 수 있다라고 설명할 수 있고 이러한 행위를 모형화라고 한다.
시계열 분석 과정 vs 회귀분석과정
시계열 분석과정은 크게 3가지로 나눈다.
1. 모형 식별
2. 모형에 대한 추정(적합)
3. 모형 진단
이 세개의 과정을 통해 모형을 결정하고, 추정하고 예측하는데 사용된다.
이런 내용이 시계열 분석 과정에 포함되어 있다.
시계열 데이터를 한번 살펴보자.

시계열 분석에 대한 수업을 듣기 전의 지식으로
주어진 데이터의 기간 이후로 미래의 강수량값은 어떻게 될 것 인지 생각해보자.
먼저 데이터의 평균을 내어 그 값을 예측값이라고 생각해볼 수 있다.
그러나 조금 더 나아가서 생각해보자.
데이터의 평균을 구했으면 주어진 데이터의 표준편차를 구해서
평균으로부터 해당 범위 내에서 값이 나타날 것이라고 생각해 볼수도 있을 것이다.
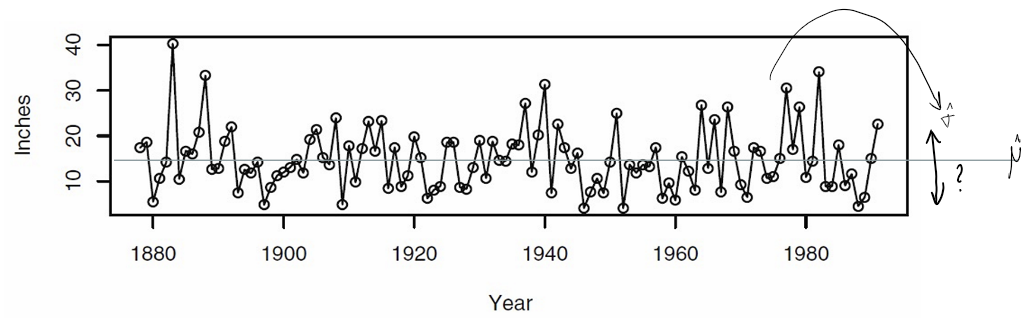
그리고 예측값이 예를들어 90%의 확률로 해당 범위에 나올것이다라는 얘기를 해보고 싶은데
(즉 신뢰구간을 구하고 싶은데)
해당 이야기를 하기위해선 "확률의 분포"가 있어야 한다.
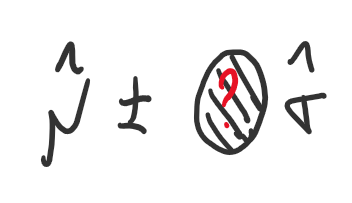
이런 상황에서, 다음과 같이 생각해 볼 수 있다.
정규분포로 근사할 수 있는 자연현상이 많다는 의견에 공감하게 된다면,
해당 분포는 정규분포가 아닐까 생각해볼 수 있고
정규분포로 가정하고 정규성 검정을 진행해 볼 수 있다.
이때, 귀무가설을 H0: 데이터가 정규분포를 따른다.
대립가설을 H1: 데이터가 정규분포를 따르지 않는다 라고 설정한뒤,
그결과 데이터를 정규분포로 볼 수 있는 상황이라고 생각해보자.
정규분포의 모수는 '평균' 과 '표준편차' 2가지이다.
즉 추정해야할 모수의 갯수가 2개이다.
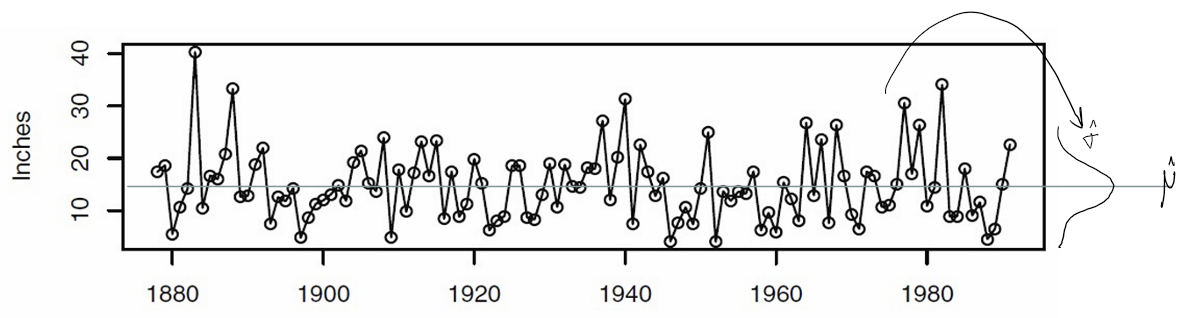
이렇게 추정된 정규분포를 통해서, 위의 그림처럼 해당 구간에서 데이터가 어떠한 확률로 나타날 것이다라고 이야기해볼수 있을 것이다.
여기까지가 시계열 분석 수업을 듣기전에 다음의 예측값에 대해서 생각해 볼수 있는 이야기들이었다.
그런데 앞서 시계열 자료에서 인접한 값들은 서로 연관이 있다.
(데이터들이 서로 연관되어 있다.)

이 연관성을 반영한 모델이 "시계열 모형"이 된다.
시계열 모형도 아까 정규분포처럼 모수가 있다.
정규분포에서 평균과 표준편차를 추정해본 것처럼
시계열 모형에서도 그 안의 모수를 추정해야한다.
추정을 다 했다면, 해당 시계열 모형으로 다음값을 예측하고 해당 모형을 기반으로 어떤 예측 구간을 계산한다.
(사실 앞서 정규분포라는 모형으로 예측해본 값은 iid 자료라는 가정하에서 만들어진 결과값이다.)
즉 데이터 사이의 연관성 반영 여부가 기존의 분석과 시계열 분석의 큰 차이점이 된다.
그런데 앞서 Los Angeles 지역 연간 강수량 그래프를 보면, 연관성이 존재하는지 그렇지 않는지
눈으로 확인하기 어렵다.
연관성이 있다라는 말은 서로 관계가 있다는 말인데 이를 확인해 볼 수 있는 통계량들이 있다.
우선 연관성을 볼 때, 가장 많이 쓰이는 것이 '자기상관함수'이다.
다음 시계열 자료를 살펴보자
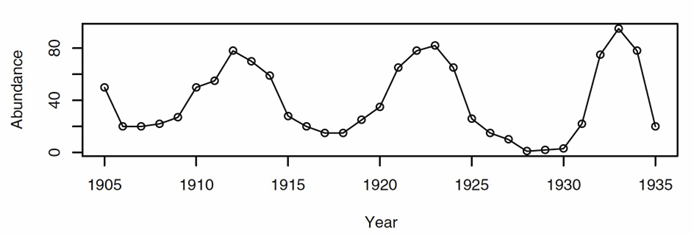
해당 시계열 자료에서
다음 값을 손으로 그려볼 수 있을 정도로 데이터는 주기를 갖는 것 같다.
그래프가 주기함수 형태인 것 같아서 모형 중에 회귀모형을 한번 사용해 보자.
회귀모형이란 관심 대상이 있을때,
관심 대상에 영향을 끼치는 변수를 설명변수라고 쓰고
관심대상과 설명 변수의 함수 관계를 찾는 것이 회귀 분석이다.
보통 관심대상을 종속변수라고 하고, 관례적으로 Y로 많이 표현되며,
설명변수는 X로 주로 많이 표현된다.

이때 물결표시에 주목하자.
수학적 모형과 통계적 모형은 다르다.
만일 해당 식에서 물결 대신 등호가 붙는다면, X = 5일때 정확히 Y값이 하나 나오게 된다.
그러나 데이터를 관찰해보면 X값이 같아도 Y값이 다르게 나타날 수 있다.
즉 X는 Y에 영향을 미치지만 모든 것이 X로만 결정되지 않는 점을 생각해야한다.
X 이외의 나머지 요소 , 다시 말해서 X로 설명할 수 없는 요소들은 Y에 분명히 영향을 미칠 것인데
설명할 수 없는 나머지 부분들이라고 하여, 오차항으로 생각한다.
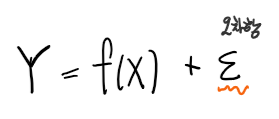
X가 동일해도 Y는 여러가지 값을 가지게 되는데, Y값들의 차이를 만들어내는 부분이 오차항이 되며
오차항은 확률분포를 만들어 낸다. 따라서 해당 통계적 모형에서 random 부분을 오차항이 담당하게 되며
결과적으로 Y도 random한 값을 가지게 된다.
---
시계열 자료를 집합으로 표기한다.
시계열 자료는 시간의 흐름에 따라 얻어지는 자료이므로 특정 시간만 관찰하지않고 인덱스 t를 통해
여러개의 값을 관찰한다. 이 여러개의 값을 집합으로 표시한다.
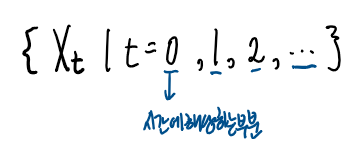
시계열 자료를 대문자, 소문자로 쓸 수 있다.
관찰된 값들, 실제로 얻어진 값들은 소문자로 표기하고
아직 관찰되진 않은 값, 확인해야할 값들(관측할 값), 아직 모르지만 알 수 있는 값은 대문자로 표기한다.

따라서 {xt}는 이미 얻은 값이므로 상수가 되며,
{Xt}는 어떠한 값이 나오는지 모르므로 확률변수가 된다.
iid자료와 시계열자료를 앞서 비교해보았는데 각 자료들이 주어졌을때
통상 어떤 목적을 가지고 분석을 진행하는지 알아보자.
시계열 자료의 특징은 데이터들이 연관되어 있는 반면,
iid 자료에서 맨 앞의 i는 independent의 약자로 관계가 없다를 뜻한다.
iid 자료 또한 대문자, 소문자로 나타내고 표기에 대한 의미 역시 시계열자료와 같지만

iid 자료는 관측된 데이터 x로부터 표본평균, 표본분산 등 통계량을 계산하고
이 계산된 값으로부터 확률변수의 분포를 만들어 내는것에 관심을 두고있다.
반면
시계열 자료는 데이터끼리 상관되어 있기 때문에
이 종속관계를 나타낼 수 있는 모형화에 주된 관심을 두고 있다.
기본적으로 시계열 자료는 인접할수록 관계가 강해지는 경향이 있다.
관계가 멀리 떨어져 있을수록 약해지나
그 관계의 정도에 따라 데이터를 나눌 수 있다.
관계가 빠르게 감소하는 경우 : short range dependence 라는 특징을 가진 자료이고
관계가 천천히 감소하는 경우: long range dependence 라는 특징을 자료이다.
나중에 배울 AR, MA, ARMA, ARIMA 모형은 short range dependence 자료에 잘 적합이 되고
Long range dependence 데이터는 Long range 모형에 적합을 시켜야한다.
즉 시계열 자료도 어떤 특징을 가지는가에 따라서 모형을 잘 선택해야한다.
'시계열자료분석' 카테고리의 다른 글
| 시계열_ch4_4.2 Moving Average Processes (0) | 2025.10.09 |
|---|---|
| 시계열_ch4_4.1 General Linear Processes (1) | 2025.10.09 |
| 시계열_ch2_2.3(Stationarity) (0) | 2025.10.08 |
| 시계열_ch2_2.1 , 2.2 (0) | 2025.10.07 |
| 시계열_ch1_introduction_(2) (0) | 2025.10.05 |