chapter 4장에선 정상성을 가진 시계열 자료에 적합한 모형들을 소개한다.
앞서 모형들이 만들어내는 확률과정이 정상성을 가진다면
그 모형을 stationary model이라고 불렀는다.
소개될 시계열 모형들이 과연 staionary model인지 확인해가면서 모형을 소개해보기로 한다.
우선 첫번째 모델은 선형 모형이다.
4.1 General Linear Processes
선형모형은 다음과 같이 표현한다.
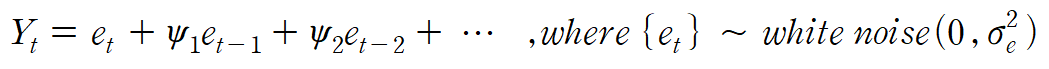
위와 같이 white noise의 선형결합으로 정의되는 확률과정을 선형과정(Linear process)라고 한다.
t시점의 확률변수 Yt는 t시점의 white noise, t시점 이전의 white noise 값들을 선형결합하여 만들어졌다.
Yt는 random한데 , 그이유는 white noise가 random하기 때문이다.
white noise가 어떠한 값을 가지는지 모르는 상황이지만 white noise의 정의에 따라
각시점의 확률변수 et, et-1, et-2, 의 평균은 0이며 각 시점의 확률변수의 분산도 일정하다.
(보통 기호로 확률변수를 ε 로 표현하는데 이경우는 e로 적게 되었다.)
그리고 위의 식을 보면 Yt가 무한합으로 정의되었다.
그렇기 때문에 Yt의 값이 무한히 커질수도 있는 상황이 생겨버리면 Yt가 정의되지 않을 수 있다.
Yt가 정의되는가의 여부는 계수 Ψ 가 결정한다.
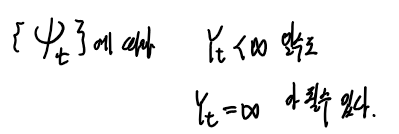
Ψ는 실수(real number)이다.
따라서 실수를 나열한 { Ψt}는 실'수열'이 된다. ({Xt}는 확률변수열을 나타내고 집합으로 표현하면 확률과정이된다.)
해당 모형에서 Yt가 값이 정의되려면 계수 Ψ의 절댓값의 합이 수렴해야(발산x)한다.
구체적으로 말하면 다음과 같다.

계수들의 절댓값의 합이 수렴한다면 Yt가 정의될뿐만아니라, Yt의 기대값도 정의된다.
더 강한 조건인 계수들의 제곱의 합이 수렴하는 조건일 경우 ,
Yt, Yt의 기대값, Yt의 제곱의 기대값도 정의가된다.
Yt^2의 기대값이 정의가 된다는 점은 Yt의 분산을 다루는데 있어서 중요하다.
그 이유는 분산의 식을 통해 알 수 있다.
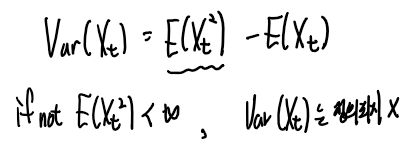
(참고로 확률변수의 기대값은 정의되었지만 분산의 기대값은 정의되지않은
확률변수의 분포가 존재한다.)
그리고 계수의 절대값의 합이 유한하다면, 계수의 제곱의 합도 유한하므로
이번 수업에선 계수들의 절대값의 합이 유한하다고 가정한다.

<계수의 절대값의 합이 유한하다면, 계수의 제곱의 합도 유한한 이유>

이 상황에서 선형과정(linear process) {Yt}가 정상성을 가지는 지 확인하자 .
정상성의 조건 3가지를 다시 떠올리자
①. 확률변수의 기댓값이 일정하다
②. 확률변수의 분포가 일정하다
③. 두 확률변수간의 선형 상관관계는 h에만 의존하는 함수로 표현되어야한다
먼저 조건 ①부터 확인하자.

조건 ②를 확인하기전에 정상성의 조건과 제시된 모형으로부터 세울수 있는 등식들을 정리해보자.
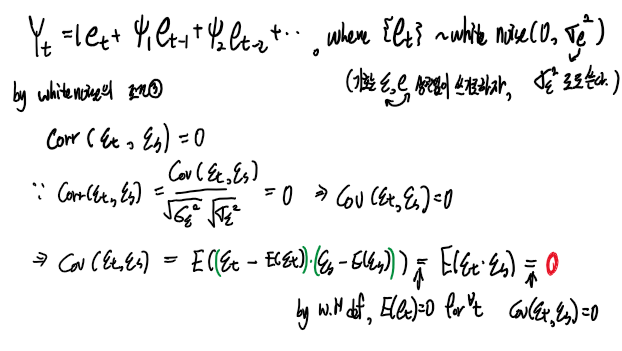
조건 ②를 쉽게 증명하기 위해서 우선 도움되는 등식들을 다시 정리해보자.
(백색잡음의 정의와 공분산의 정의 식을 다시 생각해보고 , 해당 모형의 상황을 생각하면 아래와 같은 식을 도출할 수 있습니다.)
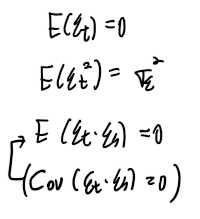
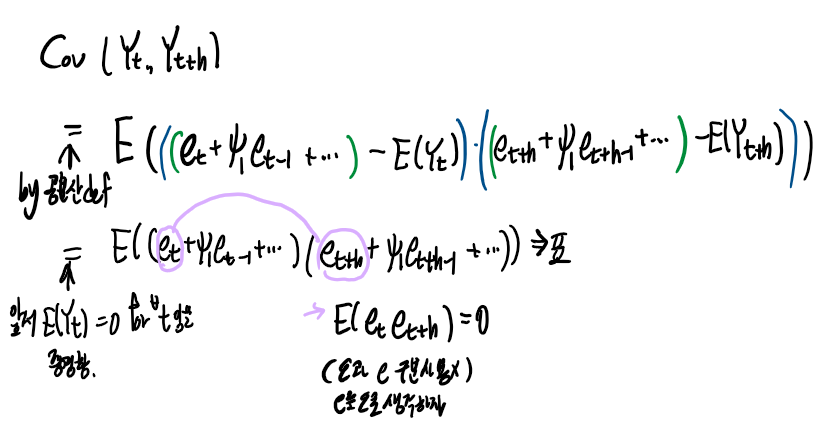
공분산을 기대값으로 표현할 수 있고 이제 기대값 안쪽의 식을 전개하고 위에서 언급한 식들을 활용해서 간단하게 표현하면 되는데
전개항들을 표로 표현해보기로 한다.
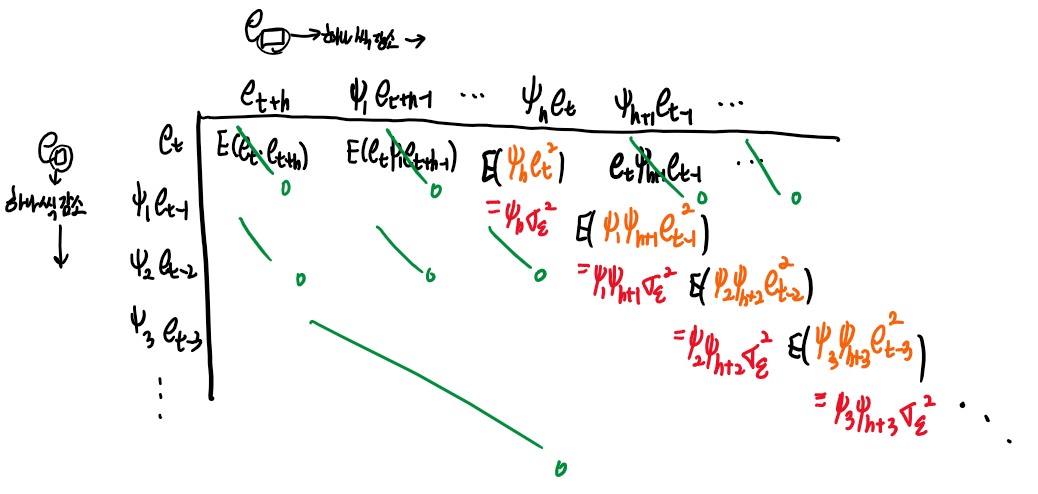
즉 공분산의 식을 빨간색 항들의 무한합으로 표현할 수 있으므로 다음과 같이 표현할 수 있다.
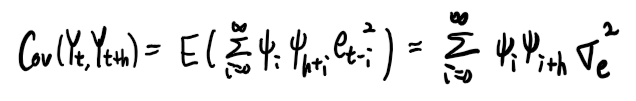
h= 0 을 대입하면, Yt의 분산 (Var(Yt)) 이 나오고 값은 시간에 따라서 일정함을 알 수 있다(정상성조건 ② 만족)
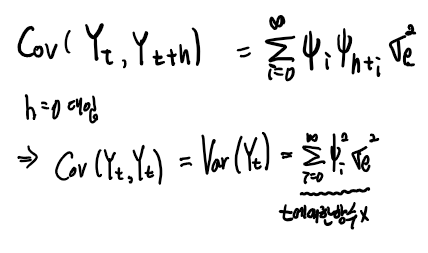
이렇게 구한 공분산, 분산 식을 통해서 상관계수 식을 구하면 다음과 같다.

h만의 함수로 표현되므로 정상성 조건 ③을 만족함을 알 수 있다.
이렇게 해당 모형에서 만들어진 확률변수들의 분산, 공분산, 상관계수, 기대값을 구해보았는데
쓰면서 느꼈지만 계수들의 합이 유한해야 Yt가 정의될수 있으며,
정의된 Yt가 정상시계열을 가질 수 있음을 알 수 있다.

예제를 풀어보자


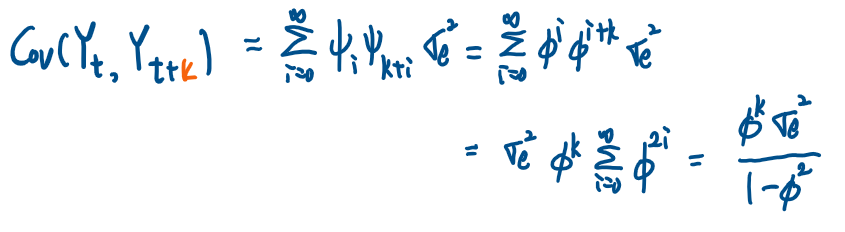
해당 예제에서 기대값, 분산, 상관계수의 식을 계산해보았더니
해당 모형이 만들어낸 {Yt}가 정상성 조건을 가지기 위해서는 Φ의 절댓값이 1보다 작아야함을 알 수 있다.
이제 상관계수를 구했다면, 자기상관함수 (ACF)를 그려볼 수 있다.
시차에 따라서 상관계수값을 그려주면 된다.
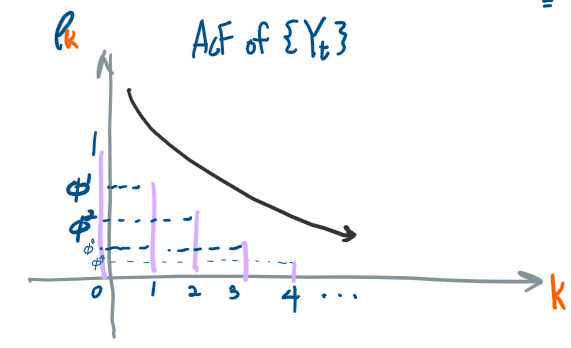
상관계수가 지수적으로 감소함을 알 수 있다.
'시계열자료분석' 카테고리의 다른 글
| 시계열_ch4_4.3 Autoregressive Processes (1) | 2025.10.11 |
|---|---|
| 시계열_ch4_4.2 Moving Average Processes (0) | 2025.10.09 |
| 시계열_ch2_2.3(Stationarity) (0) | 2025.10.08 |
| 시계열_ch2_2.1 , 2.2 (0) | 2025.10.07 |
| 시계열_ch1_introduction_(2) (0) | 2025.10.05 |