chapter4는 반복적으로 말하면
정상성 특징을 가진 데이터에 상대적으로 잘 적합한 모델들을 소개한다.
4.1절에 General Linear model은 이론적인 모델이고
4.2절에 Moving Average model은 실제 데이터분석에 사용되는 모델이다.
4.3절에서도 실제 데이터분석에 사용되는 모델 중 하나를 소개하고 있다.
4.3 Autoregressive Processes
(복습) Processes : 앞에 Probability가 생략되어 확률과정이라고 불리며, 확률과정이란 확률변수들의 집합을 뜻한다.
그리고 더 앞에 수식어인 Autoregressive가 붙는데 한국말로 자기회귀라고 불리며
Autoregressive Processes(자기회귀과정)은 확률과정 중 하나이다.
자기회귀과정이 만들어내는 확률변수 Yt가 어떻게 만들어내는지 서술된 식은 Autoregressive model (자기회귀모델)
즉 모형이 되고 , 자기회귀모형은 다음과 같다.

확률변수 Yt는 t시점의 전값, 즉 과거값 p개들의 선형결합으로 만들어진다.

모형에서, Yt-1 , ... , Yt-p 과거 시점들의 선형결합부분이 모델의 핵심부분이고 모델링한다는 뜻은 해당 f가 어떻게 구성되었는지 만들어내는 작업을 의미한다.
이때 et부분이 없으면서 p = 1인 상황을 가정해보자.

그럼 등비수열의 점화식 형태로 보인다.
만일 초기값 Y0 가 주어지면 t시점에서의 Yt값도 그냥 결정될 것이다(확률적x)
현재 t시점에 있는 상황이라면
t-1, t-2, --- | t시점 이전의 값들은 '과거값'이므로 이미 알고있는 값들이 될것이고
t+1, t+2, ... t시점 이후의 값들은 등비수열식에 따라서 현재값에 공비만 곱해주는 형식으로 값을 알게될것이다.
즉 et가 없어진 상황에선 해당 확률모형은 수학적인 모형이 되버린다.

그러나 우리는 다음과 같은 f(Yt-1, ..., Yt-p)이라는 모형을 만들어도 이 모형(f)만으로 Yt을 설명할 수 없는 부분이
반드시 존재한다. f가 설명할 수 없는 부분을 다 몰아서 설명하고자 et를 Yt를 설명하는 모형안에 넣기로 한다.
그리고 et는 white noise를 따르고, 어떠한 값이 나올지 모르는, 즉 random한 값이므로
Yt 역시 값을 모르게되는 random한 현상이 나타난다.
Yt의 random한 점이 et로 인하여 나타났다고 생각할 수 있다.
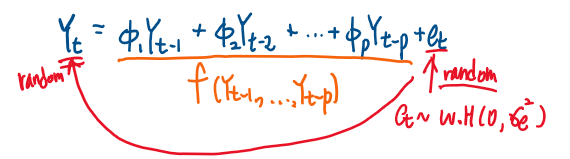
위의 모형으로 정의된 확률변수(Yt)들의 집합, 확률과정을 차수가 p인 autoregressive process라고 한다.
표기는 다음과 같이 쓴다.

추가적으로, 모든 t에 대해서 et는 Yt-1, Yt-2, Yt-3 , ... 즉 t시점 이전의 확률변수값과 독립이다라고 가정한다.
직관적으로 왜그럴까 생각을 해보면 et는 t시점에 튀어나온 값이므로 t시점 이전의 확률변수들 Yt-1, Yt-2, ..은 et와 관련이 없다.
반면 t시점에 보게될 값은 Yt는 et로 만들어졌으므로 (∵ Yt <-- f(Yt-1, ..., Yt-p) + et )
자연스럽게 Yt와 et는 독립이 아님을 알 수 있다.
이러한 사실로부터 AR(q) 모형에서 수학적으로 이론을 풀어나갈때 쓰이는 테크닉을 다음과 같이 배울 수 있다.
(나중에 기대값, 공분산, 등 구할때 쓰일 예정)
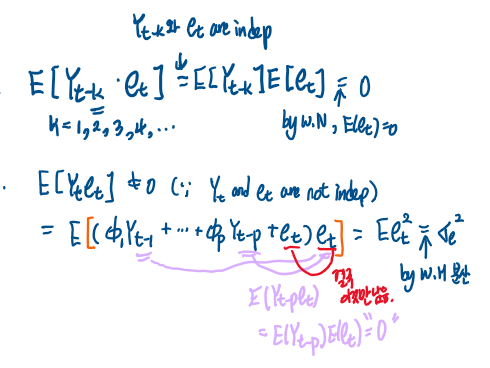
테크닉이용해서, 이번에도 AR모형에서 만들어진 확률변수 Yt의 기대값, 공분산, 상관계수를 구하기전에
생각해봐야할 것이 있다.
AR모형은 계수에 따라 정상성이 결정된다는 사실이다.
(비교 : 앞서 {Yt} ~ MA(q) , 이동평균모형을 따르는 확률과정은 항상 정상성을 가짐을 수학적으로 보인적이 있다. )
즉 모형식에서 Φ 에 따라서 내가 관찰하려고하는 AR 과정의 성질이 달라진다.
예제) Φ = 1 인경우와 Φ = 0.5 인경우에서 AR(1) 을 따르는 확률과정이 정상성을 가지는지 한번 살펴보자.
먼저 Φ = 1인 경우,

마지막 식을 잘 보면, 결국 해당 식은 white noise들의 계수가 1인 선형결합 식으로 나타낼 수 있다.
이 말은 즉 해당 확률과정은 Linear process 임을 뜻한다.
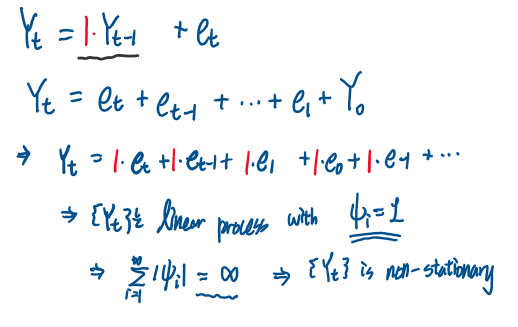
그리고 계수들의 절댓값의 합이 발산하므로, 해당 확률과정 {Yt}는 비정상성을 갖는다.
해당 확률과정을 path 1개로 시각화해보면 다음과 같다.
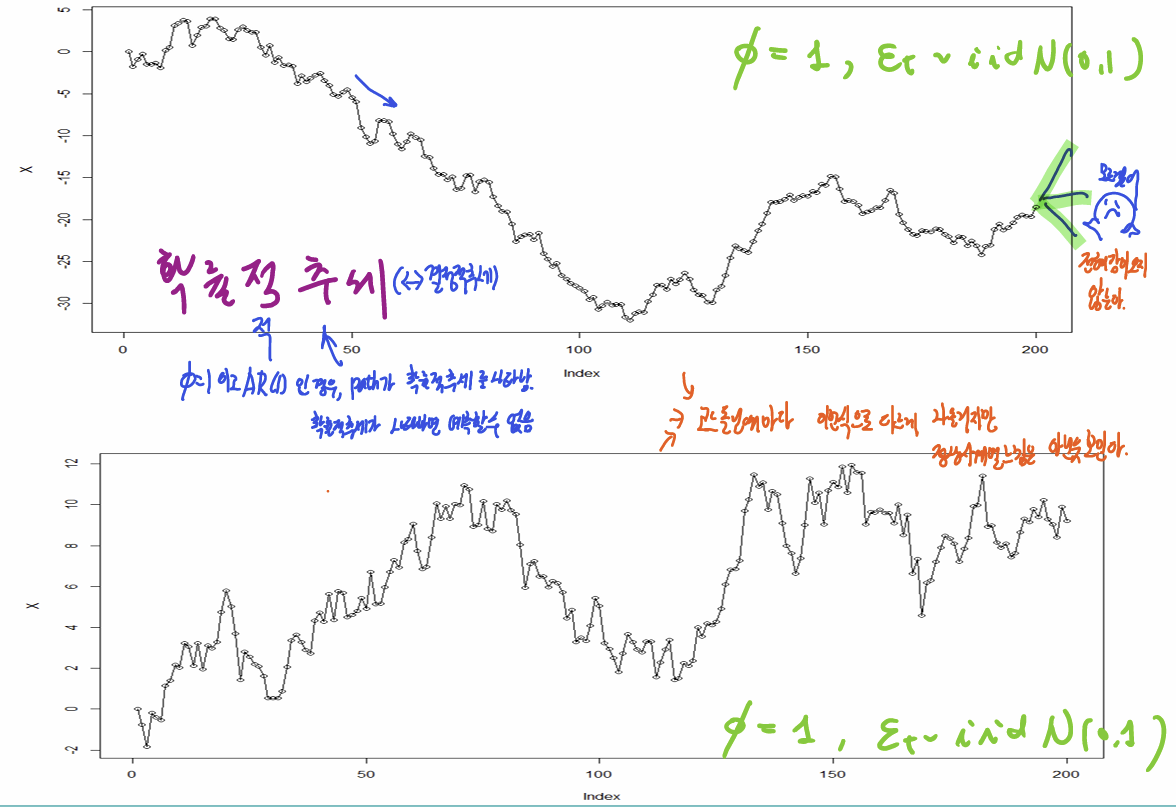
path 2개를 각각 하나씩 시각화해본 그래프이다.
각 path에서 {Yt}는 모두 정상 시계열인 것같아 보이지 않는다.
추세가 있는것 같은데 그 다음값을 설명하기 어려워보인다.
이런 추세를 확률적 추세라고하고 , 확률적 추세가 나타난다면 예측할 수가 없다.
Φ = 0.5 인경우,

해당 모형의 점화식을 풀어서 마지막식을 보면, 계수가 (1/2)^k 으로 표현된 선형모형임을 알수 있고,
계수들의 절댓값의 합은 무한합이지만,
무한등비수열의 합공식을 이용한다면, 유한한 값을 얻게된다.( 왜냐면 현재 공비가 |1/2| < 1 이므로, 해당 무한등비수열의 합은 수렴한다) 즉 계수들의 절댓값의 합이 유한한 값을 가지므로, 해당 확률과정 {Yt}는 정상성을 갖는다.
정리하면 다음 그림과 같다.
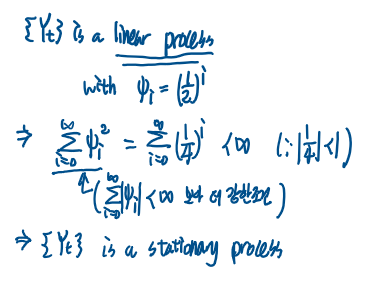
실제로 해당모형에서 나온 확률과정을 path 1개로 시각화해보면
다음 그래프처럼 정상성을 가지는 것 같아보인다.( ACF가 나타나있지않으므로 종속관계는 잘 모를 수 있다.)

이렇게 AR(p) 모형은 모형의 계수 ( Φ1, ..., Φp)에 따라 정상 확률과정이 되기도 하고 비정상 확률과정이 되기도 한다.
그런데 여기서 정상 시계열을 만족하기 위한 조건
(ex. 정상성의 정의, 계수들의 절댓값의 합의 유한한 값을 가져야함) 을 앞서 배웠는데
하나 더 배워야한다.
그전에 특성함수의 정의를 배워야한다.
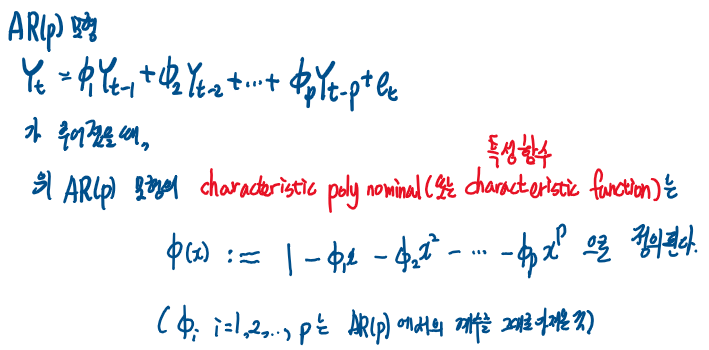
이 상황에서 AR(p) 모형의 특성방정식은 다음과 같이 정의된다.
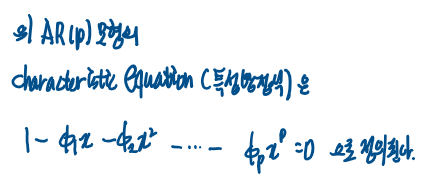
그다음 복소평면에 대해서 배워야한다.
복소수는 어떻게 표현할 수 있을까?
a+ bi 로 표현할 수 있다. (i = √(-1) 이다.) 이때 a, b는 실수이고
a+bi라는 복소수는 결국 실수 a, b에 의해서 결정이 된다.
따라서 a+bi는 순서쌍 (a,b )라는 하나의 순서쌍을 생각해볼 수 있고,
순서쌍을 좌표평면에 나타낼 수 있다.
a+bi에서 a가 실수부분 , b가 허수부분을 나타낸다.
좌표평면의 점 (1,1)을 생각해보자
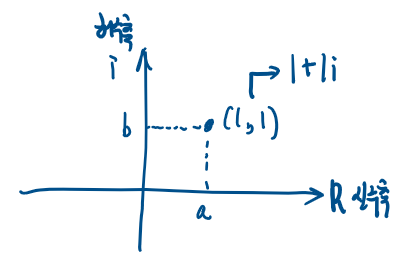
그럼 "해당 점의 위치는 (1,1)이다" 라고 생각할 수 있지만
복소수와 연결시키면 해당 점은 1+1i 와도 연결이 된다고 생각해볼 수 있다.
따라서 순서쌍을 복소수 평면 위로 올릴 수 있고, 이 옮겨진 평면을 복소평면이라고 한다.
그렇다면 해당 점은 복소수 하나인 1+1i를 가리킨다.
복소평면에서 a+bi의 절댓값 |a+bi|는 원점으로부터 (a,b) 좌표의 거리이다.
복소평면에서 단위원이란, 원점을 중심으로, 반지름이 1인 원을 뜻한다.
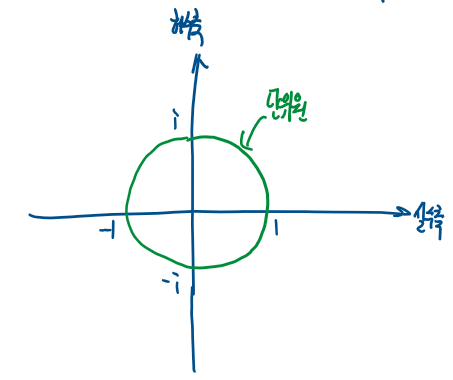
복소평면 관하여 여러가지 개념을 배웠는데 배운 이유가 다음을 설명하기 위함이다.
{Yt} ~ AR(p) 일때 {Yt}가 stationary process의 동치조건(if and only if) 은
"특성 방정식의 p개의 근이 모두 단위원 밖에 존재한다" 이다. (증명은 하지않고 우선 받아드린다.)
이전 모형에선 모형으로부터 만든 확률과정이 정상성을 가지는가 판단하기 위해선
① 기대값이 일정하다.
② 분산이 일정하다.
③ 상관계수의 식이 시차(h 혹은 k로 표현한다.)의 함수로 표현된다.
를 판단했어야 했는데
이번에는 특성 방정식의 p개의 근이 모두 단위원 밖에 존재함을 보였다면
AR(p) 모형에서 만든 확률과정이 정상성 조건을 만족한다.
예제를 통해 정상성을 만족한 {Yt} ~ AR(1) 의 기대값, 공분산, 상관계수를 구하고, ACF는 어떻게 되는지 구해보자.
정상성을 만족했다는 뜻은 이제 특성방정식의 근의 해가 복소평면의 단위원 밖에 있다고 생각할 수 있다.

바로 기대값, 공분산을 구하면 다음과 같다.
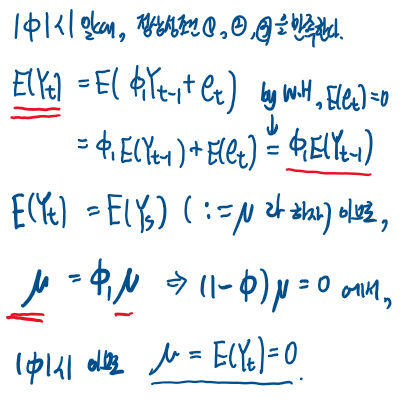

마지막 식에서 정상성 조건 ②을 이용한다.
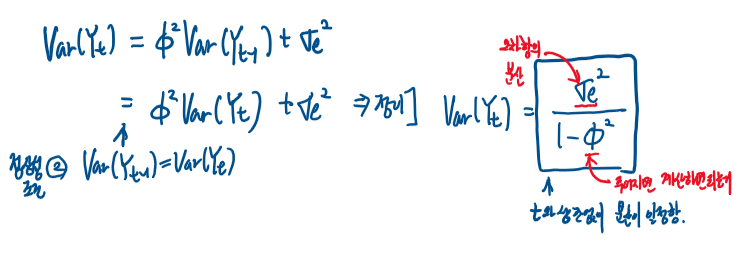
상관계수를 구하기전에 상관계수를 다음과 같이 표현하자.

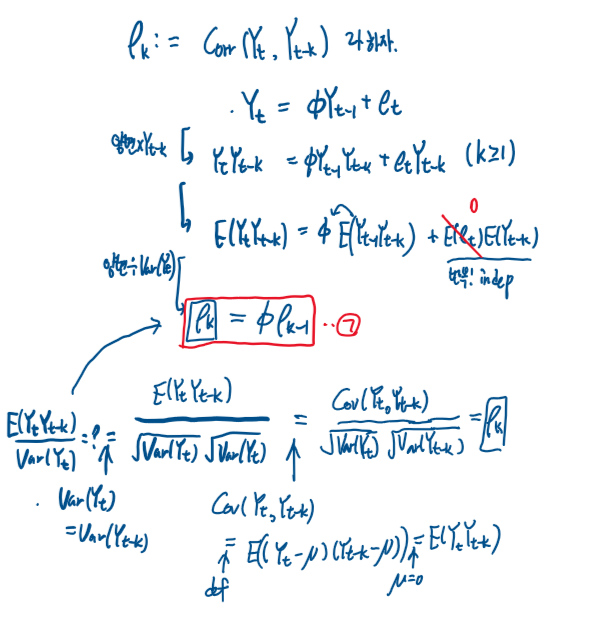
㉠ 식은 등비수열의 점화식이다.
이때 정의된 상관계수에서, ρ0 = 1임을 잊지말자( 자기자신과의 상관계수는 계산하기전에 그냥 1이다.)
그렇다면 해당 점화식을 풀면 상관계수식을 구할 수 있다.

시계열데이터가 정상성을 만족하기 위해선 | Φ | < 1 이어야하는 상황에서
상관계수식이 저렇게 주어졌으므로 해석을 하면 ,
AR(1) 모형에선 두 확률변수의 시차가 클수록, 두 확률변수의 선형 상관관계는 지수적으로 감소함을 알 수 있다.
ACF를 그려보면 다음과 같다.

이렇게 ACF 그래프를 구해보았는데 계수 Φ 의 값에 따라 ACF가 천천히 감소하거나 빠르게 감소하는 형태를 볼 수 있다.

이제 일반적으로 확장하여
{Yt} ~ stationary AR(p)의 특징을 살펴본다.
(= {Yt}가 정상 시계열 조건을 만족한다고 가정하고 정상 AR(p) 모형의 특징을 알아본다.)
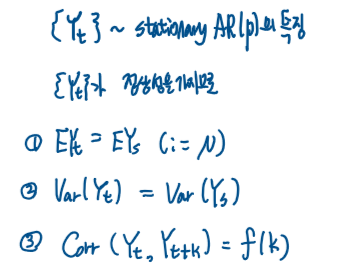
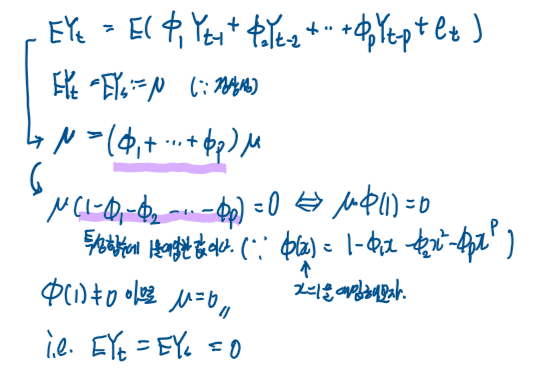

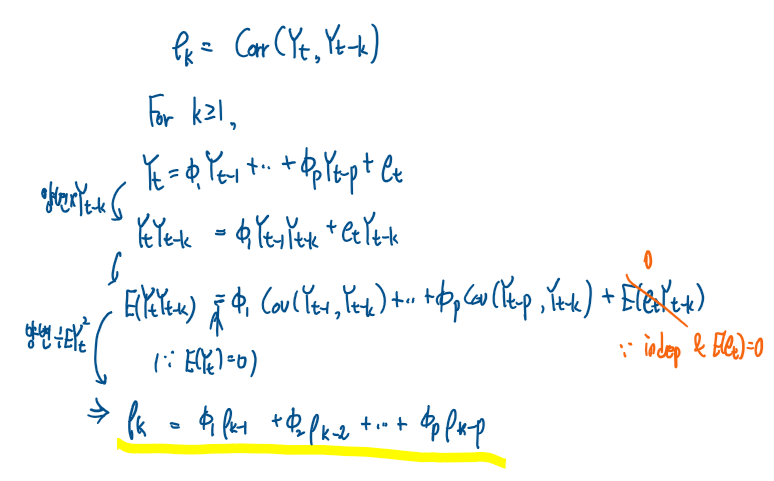
마지막 식은 점화식을 풀면 다음과 같이 상관계수식을 나타낼 수 있다.

따라서 이 상황에서 모든 1/Gi는 단위원 밖에 있다.
그러므로 다음과 같은 식이 나온다.
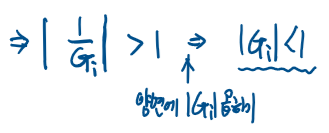
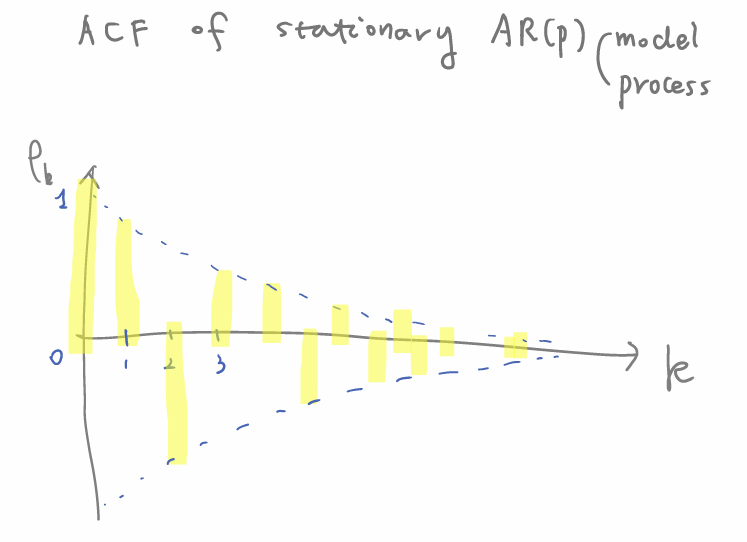
이상황에서 점화식이 풀어진 상관계수식을 다시보자,

ACF of stationary AR(p)는 k가 커짐에 따라 ρk가 지수적으로 감소하는 형태를 가짐을 알 수 있다.
따라서 ACF를 그려보면 다음과 같다.
'시계열자료분석' 카테고리의 다른 글
| Granger Causality(그레인저 인과성 검정) (0) | 2025.12.07 |
|---|---|
| 시계열_ch4 The General Linear Process Version of the AR(1) model (0) | 2025.11.09 |
| 시계열_ch4_4.2 Moving Average Processes (0) | 2025.10.09 |
| 시계열_ch4_4.1 General Linear Processes (1) | 2025.10.09 |
| 시계열_ch2_2.3(Stationarity) (0) | 2025.10.08 |