복습)
지난 시간에 배운 Auto regressive processes 에 대해서 다시 복습해보자
AR(p) 모형으로부터 정의된 정상 확률과정(stationary processes)의
(AR(p)모형에서 만들어진 확률과정은 자연스럽게 정상과정이 되지않는다.
정상성을 만족하는 조건을 만족하는 경우 정상 확률과정이라고 붙인다. )
이론적인 자기상관계수함수(=ACF)는 시간이 흐를수록 상관관계가 상당히 약해지며
그래프는 다음과 같이 그려진다.
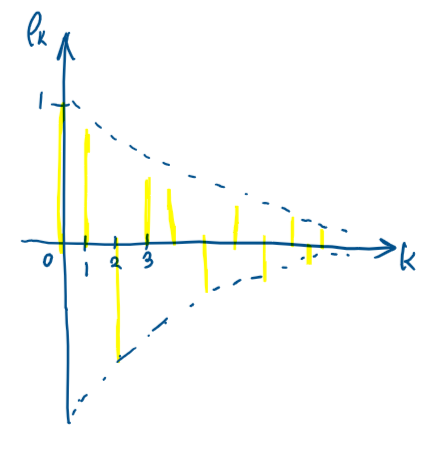
( 여러번 반복했지만 시계열 모형의 가장 중요한 특징은 ACF임을 꼭 기억하자!)
( 이론적인 ACF를 소개한 것에 주목하자.
시계열 모형을 배우는 목적은 나중에 데이터가 주어진다면, 데이터의 특징을 보고 어떤 모델을 선택해야하는지 배우는 것이다.
이때 시계열 데이터의 특징 중 주목해서 봐야할 것이 데이터로부터 계산된 ACF(=Sample ACF(SACF), SACF는 통계량이된다.)
이고
이 SACF를 여러 모형의 이론적인 ACF들과 비교해서 최대한 비슷하게 보이는 이론적인 ACF가 있다면
이에 대응되는 시계열 모델을 선택한다. )
한편 또 지난 시간에 배운 Moving Average processes 에 대해서 다시 복습해보자
MA(q) 모형으로부터 정의된 확률과정의
(MA(q) 모형에서 만들어진 확률과정은 자연스럽게 정상성을 띤다. 그래서 정상이란 말을 생략함( 앞 부분 복습) )
이론적인 자기상관계수함수(=ACF)는 q시차 이후로 모두 상관관계가 0이 됨을 알 수 있다.

간단하게 복습했다
이제 다음의 모형을 따르는 확률과정 {Yt}에 대해서 생각해보자

이 모형은 무슨 모형일까?
Yt - μ을 Zt, Yt-1 - μ 를 Zt-1, ..., Yt-p - μ 를 Zt-p로 바꿔보자

그렇게되면 {Zt} 는 AR(p) 모형에서 나온 확률과정이라고 생각할 수 있다.
( ∵ AR모형은 자기자신의 과거값들의 선형결합으로 표현할수 있다)
그다음 Yt와 Zt간의 관계에 대해 배워보자
우선 Zt는 stationary라고 가정하자.
일단 Yt를 μ 만큼 평행이동한것이 Zt이다.
그럼 직관적으로 그래프를 그려보면
평행이동하여도 종속관계가 변하지않음을 알 수 있다.

따라서 직접 계산하지않아도 다음과 같은 결론을 내릴수 있다.

그리고 앞서 AR(p) 모형을 배울때, 정상성을 가진 AR(p) 를 따르는 확률변수의
기댓값은 0 임을 배웠다.
여기서 Yt의 기댓값은 얼마일까? Yt는 Zt를 μ 만큼 평행이동시킨것이므로
계산하지않더라도 직관적으로 E(Yt) = μ 임을 알게된다!

여기까지 생각했으면 결국 {Yt}도 정상시계열임을 알 수 있게된다.
정상성은 평균,분산이 시간에따라 변하지말아야하고 자기상관관계는 시차에만 의존해야한다.
위의 식들을 살펴볼때 모두 만족함을 알 수 있게된다!
하고싶은 이야기는
앞서 AR(p) 는 평균이 0 이었다. 그러나 만일 데이터를 받았을때 평균이 0이 아닌 어떤 갓을 중심으로 나타난다고 생각이 들면서 데이터의 ACF가 '지수적으로 빠르게 감소'하는것 같다고 판단된다면 단순히 AR(p) 모형이 아닌 위의 모형을 잠정적인 모형으로 선택할 수 있을 것이다.
한편 위의 모형을 다음처럼 2가지 형태로 쓸 수 있다.

R에서는 두모형을 각각 지원하고 1번 모형을 선택했다고하면, R에선 μ 를 추정해주고
2번모형을 선택했다면, c를 추정해준다.
마지막으로 반복하면 둘중 어느모형을 쓰든 해당 모형으로부터 나온 {Yt}의
ACF의 그림은 다음과 같다.

상관계수가 지수적으로 감소하는 형태가 나온다.
다음 그래프를 살펴보자

이 그래프를 보았을때 데이터는 평균이 일정해보이지 않는것 같다.
분산도 일정해 보이지않아서 이 데이터는 비정상과정인가? 생각해볼수 있지만
그러나 사실 이 그래프는 Φ = 0.9인 AR(1)에서 데이터를 얻어와서(시뮬레이션) 그 데이터를 시각화한 것이다.
즉 데이터가 정상과정을 따른다.
앞선 내용에서 AR모형은 | Φ | < 1 이면 {Yt}가 정상과정이 된다고 배웠다.
| Φ| < 1이긴한데 Φ 가 1 에 가까운 상황이면,
정상시계열이긴하지만 위의 그래프처럼 비정상과정(non-stationary)처럼 보이는 path를 가질 수 있다.
다음 산점도 그래프를 살펴보자

이제 AR(1) 모형에서 시뮬레이션을통해 생성한 {Yt} 라는 데이터를 가지고
(Yt, Yt-1) 순서쌍을 표현한게 첫번째그림
(Yt, Yt-2) 순서쌍을 표현한게 두번째그림
(Yt, Yt-3) 순서쌍을 표현하게 세번째그림이다.
결론부터 말하면 산점도는 시차(rag)에 따라 , ACF 가 어떻게 되는지 Hint를 알려준다.
주어진 상황은

이런 상황인데,
앱실론t는 0을 중심으로 나타나니깐 Yt-1에 0.9를곱하면 Yt와 비슷할 것 같다.
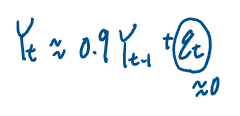
비슷한 이유로 Yt-2에 (0.9)^2 = 대략 0.8 을 곱하게 된다면 Yt와 비슷해질것 같다.

이렇게 꼭 계산아니더라도 직관을 통해서 시차간 확률변수의 상관관계를 대략 파악해볼수 있다.
이경우 시차가 1, 2, 3, .. 커짐에 따라서 과거값의 계수가 되는 Φ값이 지수적으로 감소(ex. 0.9 -> (0.9)^2 -> ... ) 하므로,
상관관계가 지수적으로 감소할 것이다라고 생각해 볼 수 있다.
다만 해당 예제에선 Φ 값이 0.9로 1에 가깝기 때문에 Φ 값이 0 에 가까운 경우보다 상대적으로 상관관계가 느리게 감소함을 산점도 그래프를 통해서도 확인해볼 수 있다.
<The General Linear Process Version of the AR(1) model>
AR(1) model을 Linear Process 로 나타낼 수 있다.
Linear Process는 백색잡음의 선형결합의 무한합으로 표현된다
MA모형도 백색잡음의 선형결합으로 표현된다. 따라서 linear process 과정을 MA( ∞ ) 과정 이라고 이야기한다.
즉 AR(1) 이 MA( ∞ ) 으로 바꿀 수 있다.

AR(1) 모형에서 출발한 Yt가 마지막에 백색잡음들의 선형결합의 무한합으로 표현됨을 알 수 있다.
무한합의 경우 , 값이 존재하기 위해선, Φ^i의 절댓값의 합이 유한(수렴) 해야한다.

AR(1)이 정상성을 가지기 위해선, 특성방정식의 근이 단위원밖에 존재하고
이를 수학적으로 풀면, 한시차이전 확률변수의 계수의 절댓값이 1보다 작아야 한다.
AR(1)-->MA( ∞ ) 변환을 생각해보면, |Φ^i|의 무한합이 유한해야한다.
<The Second-Order Autoregressive Process>
AR(2) 모형을 언급하고 , AR(2)모형의 특성방정식을 소개한뒤
AR(2) 모형에서 만들어진 확률변수의 기대값, 분산, 공분산을 구해보기로 한다.



그다음 상관계수를 구해보자

stationary AR(2) 라고 가정했으므로 G1, G2의 역수는 단위원 바깥에 존재해야한다.
따라서 |G1| <1 , |G2| < 1 이다.
상관계수식을 구했다! 그러면 AR(2) 모형의 ACF를 그려보자
상관계수는 G1에 k제곱, G2에 k제곱하여 합한 형태이므로
해당 항들이 지수적으로 감소하면 상관계수도 '지수적으로 감소'하는 형태를 취하게 된다.

그럼 위와같이 AR(2) 모형의 ACF를 나타낼수 있다.
이전장에서
AR(1) 의 ACF
AR(p) 의 ACF
그리고 지금 장에서
AR(2) 의 ACF의 형태가 모두 지수적으로 빠르게 감소함을 깨달았다.
그렇다면 만일 데이터가 주어졌고 그 데이터의 SACF가 지수적으로 빠르게 감소함을 알게되었다면
AR(?) 어느 모형을 쓸지 궁금해진다. 이부분은 추후에 따로 배우기로 한다.
추가적으로 AR(2) 모형의 상관계수의 식에 c1, c2, G1, G2 부분이 있는데 이부분을 구체적으로 어떻게 구할 수 있는지 배워본다.


'시계열자료분석' 카테고리의 다른 글
| Granger Causality(그레인저 인과성 검정) (0) | 2025.12.07 |
|---|---|
| 시계열_ch4_4.3 Autoregressive Processes (1) | 2025.10.11 |
| 시계열_ch4_4.2 Moving Average Processes (0) | 2025.10.09 |
| 시계열_ch4_4.1 General Linear Processes (1) | 2025.10.09 |
| 시계열_ch2_2.3(Stationarity) (0) | 2025.10.08 |