7.1 확률변수의 개념
관찰하고자 하는 대상을 숫자로 표현하면, 수리적으로 다루기 쉽다.
마찬가지로 앞서 배운 표본점이나 사상을 수치로 표현함으로써 수리적으로 다루고 싶어한 사람들은
숫자를 표현하는 변수로서 확률변수를 사용하기 시작한다.
즉 표본이나 사상을 수치화해볼 수 있도록 도와주는 개념이 확률변수이다.
표본을 수치화하는 경우를 생각해보자
예를 들어
동전을 두 번 던지게 된다면, 표본공간 S는 {HH, HT, TH, TT} 이다.
표본공간 S는 4개의 표본점으로 구성되어 있다.
이때 앞면 출현 횟수에 관심이 있는 경우
HH이란 표본점의 경우, 앞면 출현이 2번 발생했다.
HT라는 표본점은 앞면 출현이 1번 발생한 사상(단순사상)이다.
TH라는 표본점은 앞면 출현이 1번 발생한 사상이다.
TT라는 표본점은 앞면 출현이 0번 발생한 사상이다.

따라서 HH, HT, TH, TT는 각각 2 , 1, 1, 0 과 대응시킬 수 있다.
여기서 포인트는 표본점을 숫자에 대응시켰다는 점이다. 즉 표본점을 수치화하였다.
사상을 수치화시켜보자.
앞면 출현 횟수를 나타내는 변수를 X라고 하면,
'앞면이 1회 이하로 출현할 사상'은 'X<= 1인 사상'으로 표현할 수 있다.
이런 식으로, 사상 역시 수치로 표현할 수 있다!
관점을 뒤바꾸어서 이번에는 뒷면 출현 횟수를 관점으로 설정한다면,
그림과 같이 각각의 표본점들이 대응되는 숫자가 달라진다.

이렇게 '어디에 관심을 가지는 지'에 따라, 관심을 기준으로 삼고, 표본점이나 사상을 수치로
표현하도록 하는 수를 확률변수라고 한다.
정의는 다음과 같다.
확률변수(random variable) : 표본공간 내에 있는 각 원소에 하나의 실수값을 대응시키는 함수.
확률변수는 주로 대문자로 표시하고,
확률변수가 가질 숫자값을 문자로 표현하고 싶을 때는 다음과 같이 소문자로 표시한다.
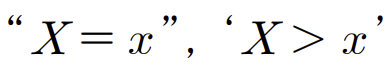
내가 생각하는 확률변수의 정의란?) 표본점 + 관점 → 확률변수
예) 주사위 한 개를 던져 나타나는 수를 X라 하자.
이때 표본공간 위에서 정의될 수 있는 확률변수는 다음과 같다.

다음의 예시와 비교해보자
예) 주사위 한 개를 던져 나타나는 수가 짝수이면 0, 홀수이면 1의 값을 나타내는 확률변수를 Y라고 하자.
이때 표본공간 위에서 정의될 수 있는 확률변수는 다음과 같다.

표본점은 1,2,3,4,5,6으로 같지만, 확률변수가 다르다는 점을 통해,
한 표본공간 위에서 정의될 수 있는 확률변수는 1개만 있는 것이 아니라 목적에 따라 다양하게 여러 개 정의될 수 있다.
이번에는 조금 특별한 확률변수의 예
예) 하나의 부품을 불량이나 양품으로 판정한다고 했을 때 확률변수 X를 나타내보자.

'불량'과 '양품' 단어 자체 안에는 숫자의 개념이 들어있지 않다.
그렇지만 불량 과 양품 각각 1, 0 이란 숫자를 부여함으로써,
불량과 양품을 확률변수로 정의할 수 있게 되었다.
특히 두 개의 가능한 값을 0과 1로 표현하는 확률변수(2진변수)를 베르누이 확률변수라고 한다.
이렇게 앞선 예들은 확률변수가 유한 개의 값을 취할 수 있는 경우였지만,
표본점이 무한 개라서 확률변수도 무한 개의 값을 취할 수 있는 경우도 있다.
밑의 예를 살펴보자.
예) 하나의 주사위를 5의 눈이 나타날 때까지 던지는 시행을 생각한다. 숫자 5가 나오면 S, 나오지 않을 경우 F로 표시하면 표본공간은 S= { S, FS, FFS, FFFS, FFFFS, · · · } 이 된다. 숫자 5가 나올 때 까지의 시행횟수를 X라고 하면,

주의할점은 이렇게 확률변수가 무한개이더라도 확률변수를 1 , 2 ,3, 4, 5, 처럼 연속적이지 않고 셀 수 있다는 점이다.
셀 수 있다는 점에서 이를 이산확률변수라고 말하는데
이처럼 셀 수 있는 무한 개의 이산확률변수도 있다는 점을 기억해두자
그렇다면 이제 셀 수 없을 정도로 무한히 많은 확률변수에 대해 알아보자
예) 어느 제품의 수명시간을 관측할 때
표본공간은 S = { t | t > = 0 } 이 된다.
확률변수 X 가 제품의 수명시간을 나타낸다고 하면, 1, 1.1 , 1.1123, ... 등 수명시간은 시간, 분, 초 , 등등 ..
수없이 많은 단위로 이루어져 있어서 시간을 정확히 1 , 2, 3, 4, 5처럼 뚝 끊어서 셀 수 없다.
따라서 확률변수 X의 가능한 값은 0 이상의 실수 전체가 되고 확률변수는 연속적으로 움직인다.
또한 표본점 그 자체가 확률변수의 값이 된다. 이러한 확률변수를 연속형 확률변수라고 한다.
예) 속도탐지기에 걸리는 과속차량들 사이의 시간간격을 확률변수 X라고 하면
X의 값 x의 범위는 x> = 0 이다.
해당 예제에서 주목해야할 사실은 한번 과속차량이 걸린 이후로 다음 과속차량이
안 올 수 있다는 점이다. 따라서 확률변수 X가 무한대로 갈 수 있다.
내용을 정리해보자.
이산표본공간: 표본공간이 유한 개 혹은 셀 수 있는 무한개의 원소로 이루어짐
연속표본공간: 표본공간의 어떤 구간 내의 모든 실수를 포함
확률변수의 값만을 생각하였을 때 확률변수를 두가지로 나눌 수 있다.
이산형 확률변수 : 확률변수가 취할 수 있는 값이 유한하거나 또는 무한히 많더라도 하나씩 셀 수 있는 경우
연속형 확률변수 : 확률변수가 연속적인 구간 내의 값을 취하는 경우
( 높이, 무게, 온도, 거리, 수명 등 주로 측정자료 )
7.2 이산형 확률분포
그렇다면 이산형확률변수의 확률을 어떤 식으로 생각해 볼 수 있는지 학습해보자
이를 나타내는게
이산형확률분포이다.
이산형확률분포는 확률변수 값마다 확률값을 할당한다.(= 값마다 확률값이 정의됨) 이를 '확률분포함수'라고 부른다.
예를 들어
1개의 동전을 세 번 던지는 실험을 생각해보자
표본공간은 8개의 원소로 되어있으며, 각 표본점 확률은 1/8로 동일하다.
이때 앞면의 출현횟수(관점)를 X라고 한다면,
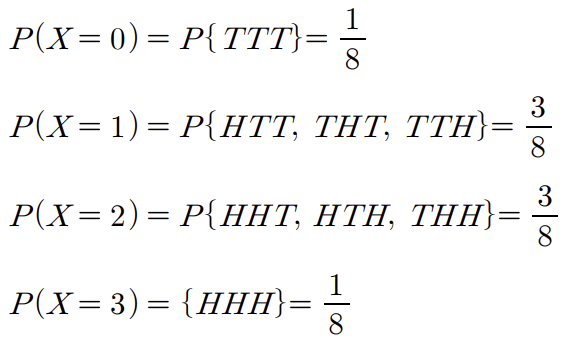
확률변수가 1인 경우 1/8이라는 확률을 할당받았고
확률변수가 2인 경우 3/8이라는 확률을,
확률변수가 3인 경우 1/8이라는 확률을,
확률변수가 3인 경우 1/8이라는 확률을 할당받았다.
이를 표로 나타내면
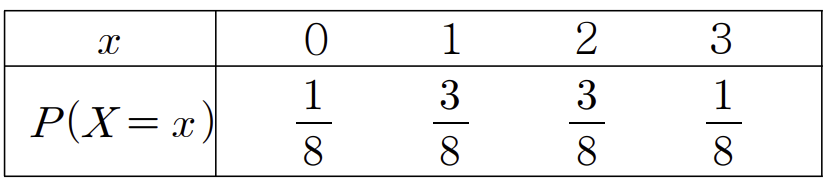
해석) x에 따라서 (= X가 어떤 값을 갖는가에 따라서) 확률이 달라진다.
즉 확률변수의 값에 따라서 확률이 대응된다.
이는 다시, x에 대한 함수로 생각해볼 수 있다. 이때 이 함수를 확률분포라고 얘기한다.
(확률분포는 함수다!)
f(x)가 다음과 같은 조건을 만족할때, f(x)를 확률변수 X의 확률질량함수, 확률분포라고 한다.

3번 조건은 X와 x와의 관계를 나타낸다.
X안에 x가 들어있을텐데, X가 x와 같아질때마다 확률을 나타낼수 있다는 것을 뜻한다.
x가 확률을 갖는 상태를 의미한다.
확률분포에 이어서 누적분포함수에 대해 알아보자.

누적분포함수는 F(x)로 표기하고 의미는 특정한 한도(특정 확률변수) 이하의 확률을 의미한다.
이때 확률변수는 이산형 확률변수이기때문에, 확률변수의 확률은 값에 대응되므로,
특정한 한도 이하의 확률은 한도 이하의 확률변수들의 각각의 확률값 들을 합하면 된다.
예를 들어서
어느 대리점에서 판매된 외제차의 50%에 디젤엔진이 장착되었다고 할 때
이 대리점에서 다음에 판매될 4대의 외제차 가운데 디젤엔진이 장착된 차의 수의 확률분포와 누적분포를 구해보자.
확률변수는 디젤엔진이 장착된 차의 수이므로 확률변수의 값은 0, 1, 2, 3, 4 로 구성되어있다.
확률변수란 이산형확률변수의 확률이 어떠한가를 보여주는 개념이고
확률이 어떠한가 생각해보면 확률변수에 각각 확률값을 대응시켜서 확률을 보여준다.
해당 사례에서 확률변수에 대응되는 확률값을 구해보면,
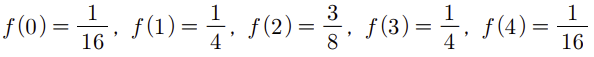
확률분포를 구했다면, 누적분포함수 F(x) 도 구할 수 있다
누적분포함수란, 특정한 확률변수 이하 범위에 속하는 확률변수에 대응되는 확률값을 모두 더한 값(확률)을 의미한다.

F(x)에서 x가 1인 경우를 생각해보자. x가 1이면 x이하의 확률변수의 범위는 0, 1이 있다.
확률변수 0의 확률은 1/16이고 확률변수 1의 값은 4/16 이므로 이 둘을 더한 값이 F(1)이다.
(x은 지금 이산확률변수이므로, x가 1이하인 확률변수의범위는 0과 1밖에 없다. 만약 확률변수가
연속확률변수라면, x는 실수값이므로, 확률변수의 범위는 x가 1이하인 모든 실수일 것이고 이를 '적분'을 통해서 고려해줘야한다. )
F(1) = 5/ 16이 나온다. 이런 방식으로 F(x)의 식을 구하면 위의 그림 같다.
확률분포를 구했다면, 누적분포함수 F(x) 도 구할 수 있었는데,
이번에는 누적분포함수를 알 수 있다면 확률분포도 구할 수 있는 방법을 알아보자.
예를들어 , f(2) 값을 알고 싶다면 이렇게 하면된다.

x 가 2 이하 F(2)는 x = 0 , 1, 2의 확률값을 더한 값(확률)이고
x 가 1 이하 F(1)은 x = 0 , 1의 확률값을 더한 값(확률)이므로 ,
F(2) - F(1) 은 2의 확률값을 가진 f(2)를 뜻한다.
7.3 연속형 확률분포
연속형 확률변수의 확률은 어떠한가에 대해서 학습해보자
이를 알기 위해서 연속형 확률변수의 확률을 구하는법은
특정한 점이 아닌 구간에 대한 확률을 고려한다는 것을 이해해야한다.
즉 확률이 적분(넓이)라는 점을 알아야한다.
왜냐하면, 연속형 확률변수의 한 점에서의 확률을 구하는게 정말 어렵기 때문이다.
연속형 확률변수로는 시간이 있는데, 시간, 분, 초 같은것을 구할수 있겠지만
1.1223435467500초 이런걸 딱 한치의 오차도 없이 정확하게 구하는것은 힘들다.
그래서 구간에 대한 확률을 고려한다
(약간 점추정은 너무힘드니깐 점추정대 구간추정을 하는느낌)
따라서 다음과 같은 식이 통용된다.
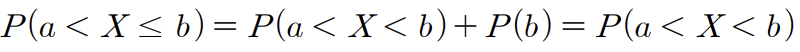
즉 구간이 끝점을 포함하는지 안하는지는 문제가 되지 않는다.
이렇게 연속형 확률변수의 확률은 f(x)자체로 정의하지않는다.
(= f(x) 자체가 확률이아니다.) 대신 f(x)의 구간에서의 면적으로 확률을 정의한다.
확률이 적분으로 주어진다
확률이 면적(적분의 기하학적 의미는 면적이니깐)으로 주어진다
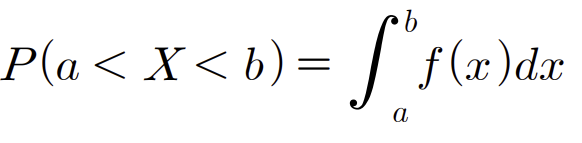
(이부분이 이해가 되어야 뒷부분이 이해가 된다. 제대로 이해해두기*)
앞서 이산형 확률변수의 확률은 어떠한가를 공부했을때(= 확률분포) 의 식하고 비교해보면 다른 것을 알 수 있다.
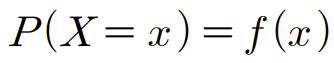
이제 확률밀도함수가 f(x)인 연속형 확률변수 X의 누적분포함수 F(x)에 대해 알아보자.

예시를 통해서 마찬가지로 확률밀도함수가 주어졌을때 누적분포함수를 구하는 법을 학습해보자.
예) 제어실험에서 반응온도(섭씨온도)의 변화에 따른 오차가 다음과 같은 확률분포를 가진다고한다.
확률밀도함수는 다음과 같다.
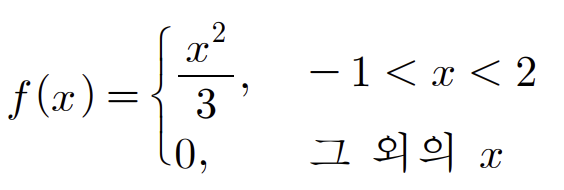
이때 누적분포함수를 구해보자.

우선 이럴땐 먼저 경계 값을 기준으로 x를 움직여서 이에따른 확률값을 관찰하면된다.
x<-1인 경우를 생각해보자.
이땐 -1이하로는 더할값이 0이므로 누적분포함수는 0이다.
그러나 -1< x < 2를 생각해보자.
누적분포함수는 특정한 확률변수 값 이하의 확률을 의미한다고 언급했다.
이 경우 특정한 한도 x 이하의 확률은 -∞ 이상 -1 이하의 확률을 더한 값과 -1에서 x까지의 확률을 더한 값을 합한 값이다.
따라서 F(x)는 다음과 같다.

x > 2 인 경우 F(x)는 x가 2이하의 확률이므로, 모든 경우의 확률을 뜻하므로 1이 된다.
식으로 정리하면 다음과 같다.
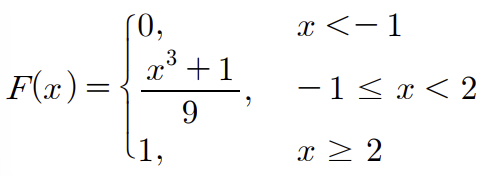
이제 반대로 누적분포함수가 주어졌을때, 연속형 확률분포(= 연속형 확률변수의 확률)를 구해보자.
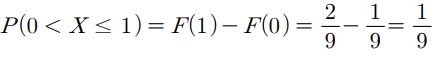
F(1)이란 뜻은 x가 1이하의 확률을 의마하고
F(0)이란 뜻은 x가 0이하일때의 확률을 의미한다.
따라서 F(1) - F(0) 은 x가 0 이상 1이하의 확률을 의미한다.
'수리통계학1' 카테고리의 다른 글
| 9강. 조건부 분포, 통계적 독립 , 여러 개의 확률변수 (0) | 2024.06.29 |
|---|---|
| 8강 결합 확률분포 (0) | 2024.06.28 |
| 6강. 전확률의 정리와 베이즈 정리 (0) | 2024.06.27 |
| 5강. 조건부 확률, 승법정리 (0) | 2024.06.27 |
| 4강. 사상의 확률, 가법정리 (0) | 2024.06.25 |