카이제곱분포
카이는 X 를 그리스어로 표현한 말이다.
χ에 제곱을 한다고 해서 카이제곱분포라고 불린다.
사실 카이제곱분포는 감마분포의 특수한 경우이다.
한마디로 감마분포의 일종인데, 카이제곱분포가 실생활에 많이 쓰여서
따로 카이제곱분포라고 이름이 붙여졌다.
(구체적으로, 카이제곱분포는 통계적 추론에서 중요한 역할을 하는데, 정규모집단의 모분산을 통계적으로 추론할때 쓰인다. 나중에 추론할때 카이제곱분포가 나오니깐 기억해두자)
즉
카이제곱분포(chi-square distribution)는
α = ν / 2 ( ν 는 양의 정수) 이며,
β = 2 인 감마분포이다.
생뚱맞게 ν가 있는데
ν는 카이제곱분포의 자유도를 나타낸다.
그래서 카이제곱분포를 자유도 ν 인 카이제곱분포라고 부른다.
카이제곱분포를 구하는 법은 감마함수에 α = ν / 2 , β = 2 를 대입하면 된다.

카이제곱분포는 감마함수의 일종이니깐
앞서 감마함수를 배울때,
감마함수의 평균은 αβ, 감마함수의 분산은 α*β^2 이라고 배웠다.
평균과 분산에
α = ν / 2 를 대입하고 β = 2 를 대입하면,
카이제곱분포의 평균과 분산을 알 수 있다.

카이제곱분포의 특징에 대해 알아야할게 2가지가 있다.
한가지는 카이제곱분포는 자유도를 크게하면, 카이제곱분포를 정규분포로 근사해서 생각할 수 있다는 것이다.
밑에 그림을 보자

보통 자유도가 30보다 클때, 카이제곱분포를 표준정규분포로 이용하여 근사할 수 있다.
두번째 카이제곱분포의 특징은 카이제곱분포표를 사용하여 계산을 쉽게 할 수 있다는 점이다.
카이제곱분포표란, 만약 자유도가 ν인 카이제곱분포에 대해서
P(X> x) 라는 확률값을 나타내는 α ( 이때 α 는 감마함수의 α 가 아님! ) 가 주어질 때 x의 값을 제시한 표를 뜻한다.
이때의 x는 특별히 기호로 다음과 같이 표시한다.

카이제곱분포표의 가이드라인?을 그림으로 나타내면 이렇다.

내가 알고자 하는 확률값 α와 주목하고싶은 ν 를
카이제곱분포표에서 찾아서
x를 쉽게 구할 수 있다.
로그정규분포
로그정규분포는 조금 헷갈릴 수 있다.
X라는 확률변수에 로그를 씌운 새로운 확률변수가
평균이 μ 이고 표준편차가 σ 인 정규분포를 따른다는 점에서
로그정규분포라고 이름이 붙었다.
근데 주의해야할점이
로그정규분포의 확률변수는 ln(X) = Y (새로운 확률변수) 가 아닌
X라는 점이다 .
즉 로그정규분포는 로그라는 껍데기? 안에
씌워져있는
X 에 대한 분포를 뜻한다.
로그정규분포를 쓰는 이유는 정규분포가 많이 쓰이지만
정규분포와 비슷하게 생긴 데이터가
정규분포를 쓰기에는 조금 아쉬울때..?
그때 로그정규분포를 쓴다.
로그정규분포의 식은 그냥 정규분포 확률밀도함수
에다가 x 대신 ln(x)를 집어넣기만 하면
안되냐고 물어볼 수 있는데
확률변수를 x대신 ln(x)로 변환이 이루어질때는
확률밀도함수를 적분을 해서 변수변환을 하는 것처럼 생각해야한다.
(뭔말인지 모르겠는데 아무튼 로그정규분포를 만들기 위해선
단순하게 정규분포에다가 ln(x)만 집어넣어서 끝났다고 생각하면 안됨)
문제풀때 조금 도움될 수 있으니깐
로그정규분포를 만드는 과정을 직접 써보자


변수를 변환한다음, 누적분포함수에 대입한다.

확률을 Y에 대하여 변수를 변환한다.
Y는 정규분포를 따른다고 했으므로 , Y를 표준 정규분포로 바꿔주는 정규화를 실시한다.


표준정규분포의 누적분포함수를 미분하면 , 표준정규부포의 밀도함수가 나온다.
이렇게 확률밀도함수의 변수를 변환하고 싶을때는
단순히 변수값을 대입하는게 아니라
누적분포함수의 변수를 변환한 다음, 누적분포함수를 미분하여
확률밀도함수를 도출해야지
제대로된 , 변수가 변환된 확률밀도함수를 구할 수 있다.
(확률변수의 변수변환은 뒤에서 나온다)
따라서 정규분포 식에 ln(x)를 집어넣은다음,
1/x를 추가적으로 곱해준 형태가
로그정규분포이다.

로그정규분포의 평균과 분산의 증명은 복잡해서 생략

주의해야할점은 로그정규분포의 평균과 분산과
ln(x) = Y 가 정규분포를 따를때의 평균과 분산을 구분해야한다.

로그정규분포의 문제를 풀어보자
사실 로그정규분포의 누적분포함수도 따로 표로 만들었다.
이를 로그정규분포표이고 이 표를 이용하면 쉽게 계산을 할 수 있다.

p(X> 8) 을 구해야하지만
누적분포를 이용하고 싶기에 해당 식을 구한다.

와이블 분포
와이블 분포는
시간이 지나면서 수명이 줄어드는 상황에 쓰기 적합한 모델이다
이전에 지수분포의 건망성에 대해서 배웠다.
지수분포의 건망성으로 인해
지수분포는 시간이 지나면서 마모가 되는 상황에 적합하지 않은 모델이다.
그렇지만 실생활에서 시간이 지나면서 수명이 줄어드는 상황은 흔한 일이므로
이를 잘 설명해주는 모델이 바로 와이블 분포이다.

주의할점이 지수분포의 β와 와이블 분포의 β는 서로 다르다는 점이다.

정확히 말하면, 일단 와이블 분포에 β = 1 을대입해본다면 ,
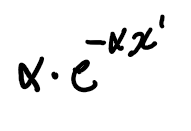
식이 이렇게 나오는데
지수분포에서 1/ β = α 를 대입한 식이 와이블 분포가 된다는 점을 통해
와이블 분포의 베타, 알파가 지수분포의 베타, 알파와 다르다는 점을 알수 있다.
와이블 분포의 누적분포함수를 따로 정리해보자
예전에도 언급했지만 연속확률변수를 가지는
확률밀도함수는 그자체로서 중요하지 않고
적분을 해야지 확률값을 도출할 수 있다.

따라서 와이블 분포의 누적분포함수는 다음과 같이 정리할수 있다.

와이블 분포의 평균과 분산에 대해서 정리해보자
증명은 평균과 분산의 정의에서 출발하면 된다.

고장률 또는 위험률
고장률 또는 위험률 에 대해서 알아보자
고장률이랑 위험률 개념은 같다 말만 다름
t 시간 까지 부품이 작동하고 잇는 상황 속에서
t에서부터 간격 Δt 만큼 더 생존할 확률에 대한 순간적 변화율이다.
조금 어려울 수 있는데 하나씩 설명해보면,
보통 일상생활의 부품같은건
시간이 지나면서 고장날 확률이 커진다.
예외적으로 시간이 지나면서 고장날 확률이 줄어드는,
마치 쓰면 쓸수록 강화되는 상황도 있다.
아무튼 그런 상황에서 주목해야할 점은
t시간이 지났을때 고장이 나지 않은 상황에서
과연 t시간을 기준으로 Δt이 지났을땐, 생존할 확률이 어떤가 궁금할 것이다.
쉽게 말하면 , 과거부터 기계를 계속 쓰고 있다가
내가 만약 품질 관리자라고 생각한다면,
앞으로 시간이 지났을때 부품이 고장날 확률이 궁금할 것이다.
Δt의 크기는 임의로 정할 수 있겠지만
Δt 를 아주 미세하게 줄여본다면 dt로 만들 수 있고
Δt 가 dt가 된 상황에서
즉 과거부터 지금까지 부품이 고장이 안나다가
지금 기준으로 아주 조금의 시간이 지났을땐
고장날 확률이 커지는지 , 작아지는지 알고 싶어 할 수있다.
쉽게말해서 고장날 추세인지 아닌지를 알고싶어하는데
그때 쓰는 지표가 바로 고장률 혹은 위험률이다.
고장률 혹은 위험률을 식으로 표현하기 위해서
먼저 신뢰도 라는 개념을 알아야한다.
큰 뜻은 없고 부품이나 생산품의 신뢰도란
규정된 조건하에서 최소한 어느 특정 시간까 지 그 부품이 작동할 확률로 ,
예를 들면, 과거부터 지금까지 기계가 잘 작동할 확률 즉 고장이 나지 않을 확률을 뜻한다.
이때 어느 특정 시점을 t라고 두고 ,
시점 t에서의 주어진 부품의 신뢰도를 정의하면 다음과 같다.
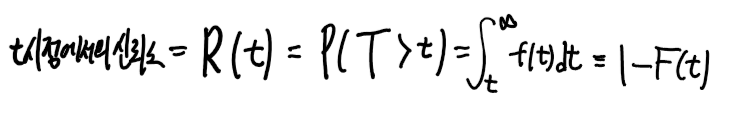
지수분포의 건망성을 학습할때,
t시점 까지 고장이 나지 않을 확률은 t시점 이후 고장이 날 확률과 같다는 점을 상기시키자.
( = ex. 하나의 부품이 8년이상 작동할 확률 = 처음 고장나기까지 시간이 8보다 클 확률)
따라서 어느 특점시점까지 고장이 나지 않을 확률인 t시점에서의 부품의 신뢰도를
P(T < t) 가 아닌 P( T > t )로 표현할 수 있다.
확률은 연속확률밀도함수의 적분한 값이므로
f(t)를 t에서부터 무한대까지 적분한 값이 t시점에서의 신뢰도가 된다.
( f(t)는 시간이 지나면서 부품이 고장나거나 , 부품이 강화되는 상황에 적합한 확률밀도함수(모델)이라면
와이블 분포이든, 뭐든 가능하다. )
신뢰도가 무엇인지 학습했으니
이제 고장률 혹은 위험률의 개념을 생각해보면서
고장률 혹은 위험률의 식을 작성해보자
부품이 t 시간까지 작동했을 때 , 구간 T = t, T = t + Δt 사이에 고장날 확률이므로
조건부 확률이다.
부품이 t 시간까지 작동할 확률은 R(t) 즉 t시점에서의 신뢰도를 뜻하고
T = t, T = t + Δt 사이에 고장날 확률 은
여러번 반복하지만, 고장이 나기까지의 시점이
t와 t + Δt 사이에 있는 특정한 시점범위에 속해야하고
고장이 나기까지의 시점 이전으로는 고장이 나지 않을 확률이므로
F( t + Δt ) - F(t) 로 표현할수 있다.
조건부확률은 따라서 이와 같고

고장률 혹은 위험률의 정의는 t가 아주 조금 변할때, 해당 조건부확률이 얼마나 미세하게 변화하는지
( = 순간적 변화률)
를 뜻하므로

이렇게 표현할수 있고
식을 정리하면

참고로 해당 식을 이용해서
지수분포의 고장률을 구해보자
구해보면 1/ β 가 나오는데
t에 따른 함수로 나오지 않고 상수가 나왔다!
이 뜻은 시간에 상관없이 확률의 추세가 변화하지 않고 ,
앞에 시간이 어떻게 흘렀든 간에 영향을 미치지 않았다는 뜻이다.
즉 지수분포의 건망성을 다시 알게된다.
이제 고장률 식에 지수분포대신 와이블 분포를 대입해보자

식이 단항식으로 나왔기 때문에
β 가 1인가 보다큰가 작은가에 따라서
시간에 따라서 고장률 추세가 변함을 알 수 있다.
한가지만 예를 들면 β 가 1보다 크면 고장날 확률이 커지므로 ,
부품이 시간이 지나면서 마모되는 현상에 적합하다고 생각할 수 있다.
'수리통계학1' 카테고리의 다른 글
| 29강 이변량 정규분포 (1) (0) | 2024.08.23 |
|---|---|
| 28장 베타분포 (0) | 2024.08.22 |
| 25강 감마분포와 지수분포의 적용 (0) | 2024.08.20 |
| 24강 감마분포와 지수분포 (0) | 2024.08.20 |
| 극좌표계에서의 이중적분 (0) | 2024.08.19 |